Facebook 架构学习
2009-04-13 10:03
232 查看
原贴:http://www.dbanotes.net/arch/facebook_arch_note.html
网址: http://www.dbanotes.net/arch/facebook_arch_note.html
在 QCon 2008 (旧金山站) 上Facebook 做的这个技术分享有不少值得借鉴的东西。所以,暂停对 QCon 北京的回顾,临时插播一贴。
设计原则
尽可能的使用开源软件,并且在需要优化的时候进行优化
Unix 哲学。包括,模块化原则;整合化原则;清晰化原则等
任何组件具备扩展性
最小化故障影响
简化,简化,简化!
架构概览
Facebook 是 LAMP 的坚定支持者,也差不多是用 LAMP (或许用 LAM2P 更适合) 实现的最大的动态站点。
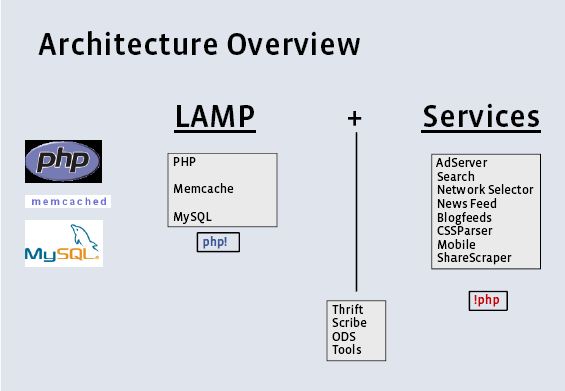
基础组件加上服务,中间用自己实现的一些工具进行粘合。其中关于运维细节的事情基本不会说出来的,这是很多公司的软实力所在。
PHP 经验
参见《Facebook 的 PHP 性能与扩展性》
MySQL 经验
主要用于做 Key-Value 类型的存储操作,数据随机分布在多台逻辑实例上,访问多数基于全局 ID 。
逻辑实例分散在多台物理主机上(超过1800台),负载均衡在物理层进行。
不做读复制。
尽量不做逻辑数据迁移(成本太高)。
不做 JOIN 操作 (豆瓣在 QCon 上也阐述了这一点)。数据是随机分布的,关联操作反而带来了极大的复杂度。
对于数据访问,主要的操作集中在最新的数据上,针对这部分做优化,旧的数据进行归档。
在中心 DB 绝不存储非静态数据。
使用服务或者 Memcached 进行全局查询。
Memcached 经验
参见我以前的笔记:Facebook 的 Memcached 扩展经验。Facebook 对 Memcached 做了不小的改进。另外,顺便说一下,前两天 Memcached 刚在 1.2.7 发布几天之后又发布了新版本 1.2.8,修正了一些问题。
一个比较有价值的是关于个人页面数据的获取的描述。这个就完全是需要做单页面 Benchmark 的细致活儿了,可能还需要产品经理能够理解工程师的"抵抗"。
获取个人信息数据:通过Cache,隐性通过用户所在的 DB 获取(基于 User-ID 获知 DB)
获取朋友连接信息:通过Cache,否则的话通过DB(基于 User-ID 获知 DB)
并行抓取每个朋友的 10个照片相册 ID ,从Cache抓取,如果失效,再从 DB 抓取(基于相册 ID)
并行抓取最近相册中的照片数据
运行PHP 把整个业务逻辑跑出来
返回数据给用户
然后是对 Facebook 非 LAMP 体系的东西做了一番介绍,基本上也开源了。最后参考两个架构图。
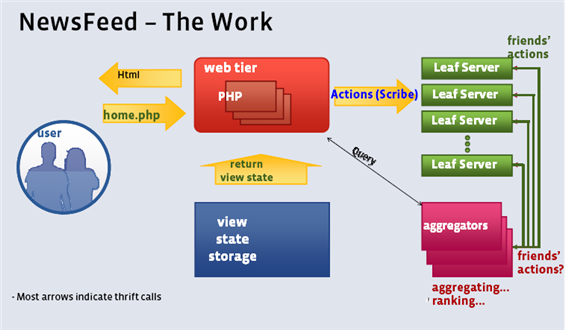
Facebook NewsFeed 的架构示意图
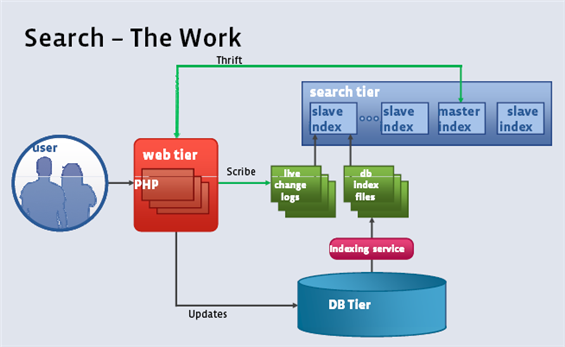
Facebook 搜索功能的架构示意图
管中窥豹,盲人摸象而已。
--EOF--
这篇 【Facebook 架构学习 】来自 dbanotes.net |

del.icio.us 收藏
By Fenng on April 12, 2009 4:10 PM
| Permalink | TrackBacks (0) |
Arch
| Edit
Generator | Trampoline
@import url(http://www.google.com/cse/api/branding.css);
自定义搜索

的评论:
NewsFeed 的架构对SNS类型的网站有很好的借鉴意义,这里的数据传输基本可以算是三角传输的实现,aggregators的作用非常大,完成了数据的合并排序。
April 12, 2009 5:03 PM
writeCommenterGreeting(commenter_name, 1626, 1, commenter_id, commenter_url);
//-->
直接匿名评论 或者 登录 评论这篇文章(OpenID、TypeKey...)
Facebook 架构学习
作者: Fenng | 可以转载, 转载时务必以超链接形式标明文章原始出处和作者信息及版权声明网址: http://www.dbanotes.net/arch/facebook_arch_note.html
在 QCon 2008 (旧金山站) 上Facebook 做的这个技术分享有不少值得借鉴的东西。所以,暂停对 QCon 北京的回顾,临时插播一贴。
设计原则
尽可能的使用开源软件,并且在需要优化的时候进行优化
Unix 哲学。包括,模块化原则;整合化原则;清晰化原则等
任何组件具备扩展性
最小化故障影响
简化,简化,简化!
架构概览
Facebook 是 LAMP 的坚定支持者,也差不多是用 LAMP (或许用 LAM2P 更适合) 实现的最大的动态站点。
基础组件加上服务,中间用自己实现的一些工具进行粘合。其中关于运维细节的事情基本不会说出来的,这是很多公司的软实力所在。
PHP 经验
参见《Facebook 的 PHP 性能与扩展性》
MySQL 经验
主要用于做 Key-Value 类型的存储操作,数据随机分布在多台逻辑实例上,访问多数基于全局 ID 。
逻辑实例分散在多台物理主机上(超过1800台),负载均衡在物理层进行。
不做读复制。
尽量不做逻辑数据迁移(成本太高)。
不做 JOIN 操作 (豆瓣在 QCon 上也阐述了这一点)。数据是随机分布的,关联操作反而带来了极大的复杂度。
对于数据访问,主要的操作集中在最新的数据上,针对这部分做优化,旧的数据进行归档。
在中心 DB 绝不存储非静态数据。
使用服务或者 Memcached 进行全局查询。
Memcached 经验
参见我以前的笔记:Facebook 的 Memcached 扩展经验。Facebook 对 Memcached 做了不小的改进。另外,顺便说一下,前两天 Memcached 刚在 1.2.7 发布几天之后又发布了新版本 1.2.8,修正了一些问题。
一个比较有价值的是关于个人页面数据的获取的描述。这个就完全是需要做单页面 Benchmark 的细致活儿了,可能还需要产品经理能够理解工程师的"抵抗"。
获取个人信息数据:通过Cache,隐性通过用户所在的 DB 获取(基于 User-ID 获知 DB)
获取朋友连接信息:通过Cache,否则的话通过DB(基于 User-ID 获知 DB)
并行抓取每个朋友的 10个照片相册 ID ,从Cache抓取,如果失效,再从 DB 抓取(基于相册 ID)
并行抓取最近相册中的照片数据
运行PHP 把整个业务逻辑跑出来
返回数据给用户
然后是对 Facebook 非 LAMP 体系的东西做了一番介绍,基本上也开源了。最后参考两个架构图。
Facebook NewsFeed 的架构示意图
Facebook 搜索功能的架构示意图
管中窥豹,盲人摸象而已。
--EOF--
这篇 【Facebook 架构学习 】来自 dbanotes.net |
del.icio.us 收藏
By Fenng on April 12, 2009 4:10 PM
| Permalink | TrackBacks (0) |
Arch
| Edit
Generator | Trampoline
@import url(http://www.google.com/cse/api/branding.css);
自定义搜索
本文相关评论|Comments(1)
sky000.wordpress.com的评论:
NewsFeed 的架构对SNS类型的网站有很好的借鉴意义,这里的数据传输基本可以算是三角传输的实现,aggregators的作用非常大,完成了数据的合并排序。
April 12, 2009 5:03 PM
添加评论
<!--writeCommenterGreeting(commenter_name, 1626, 1, commenter_id, commenter_url);
//-->
直接匿名评论 或者 登录 评论这篇文章(OpenID、TypeKey...)

相关文章推荐
- Facebook 架构学习
- 架构学习笔记—facebook
- Facebook图片存储架构的学习(转)
- Facebook&nbsp;架构学习
- 分享D瓜哥最近攒的资料(架构方面)、架构分析与设计、知名网站架构分析:Amazon网站架构学习总结、探索Google App Engine背后的奥秘、Facebook图片存储架构、优酷网架构、YouTube架构
- Facebook 架构学习
- Facebook 架构学习
- Facebook 架构学习
- Facebook 架构学习
- Facebook 架构学习
- Facebook图片存储架构的学习
- Facebook图片存储架构的学习
- Facebook图片存储架构的学习
- Facebook 架构学习
- Kubernetes架构学习笔记
- asp.net底层架构学习笔记
- 分布式架构学习之:020--服务接口设计原则
- 分布式架构学习之:024--Dubbo直连服务提供者
- 究竟啥才是互联网架构“高可用” “高并发” 学习笔记
- Shiro的学习(一) -------了解Shiro的架构