SQL开发中容易忽视的一些小地方(六)
2009-03-09 21:46
363 查看
本文主旨:条件列上的索引对数据库delete操作的影响。
事由:今天在博客园北京俱乐部MSN群中和网友讨论了关于索引对delete的影响问题,事后感觉非常汗颜,因为我的随口导致错误连篇。大致话题是这样的,并非原话:
[讨论:] delete course where classID=500001 classID上没有创建任何索引,为了提高删除效率,如果在classID上创建一个非聚集索引会不会提高删除的效率呢?
我当时的观点:不能。
我当时的理由:数据库在执行删除时,如果在classID上创建了非聚集索引,首先按这个非聚集索引查找数据,找到索引行后,根据索引行后面带的聚集索引地址最后找到真正的物理数据行,并且执行删除,这个过程看起来没有作用,只能创建聚集索引来提高删除效率,因为如果classID是聚集索引,那么直接聚集索引删除,此时的效率最高。
下班后对这个话题再次想了下,觉的自己的观点都自相矛盾,既然知道删除时,会在条件列上试图应用已经存在的索引,那么为什么创建非聚集索引会无效呢?如果表的数据相当大,classID上如果没有任何索引,查找数据时就要执行表扫描,而表扫描的速度是相当慢的,为此为了证明下这个问题,我特意做了一个示意性的实验。
创建两个表course 和course2,创建语句如下,它们唯一的区别就在于索引,course表中classID上创建了非聚集索引,而course2上没有创建任何索引。
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
--创建索引
create index IX_classID
on course(classID)
CREATE TABLE [dbo].[course2](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH2] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
实验过程:
第一步:分别给两个表插入相当的数据1000行,然后删除第500条记录。
delete course
where classID=500
delete course2
where classID=500
执行计划图如下:我们可以看到在执行删除时,数据库分为三部分:
1:查找到要删除的数据行;
2:包含一个top操作。
3:执行聚集索引删除。
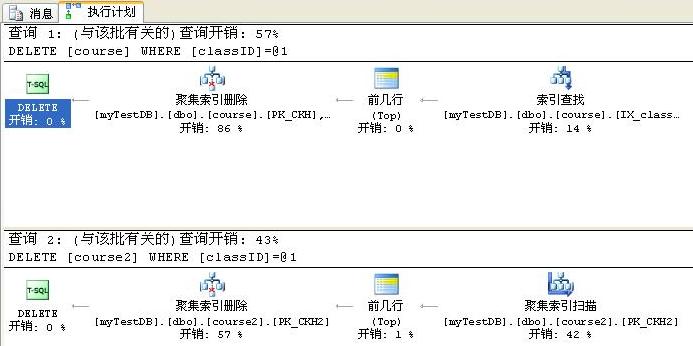
区别一:由于course表的classID上创建了索引,所以查找时按PK_classID来查找,course2表的classID由于没有任何的索引,为了查找到要删除的数据行,就只能按聚集索引查找,此时实际上是全表扫描。
区别二:系统开销不同,让人意外的是,结果表明好像白天的观点是正确的,创建了索引的coure表在开销上比没有创建索引的course2还大一点。
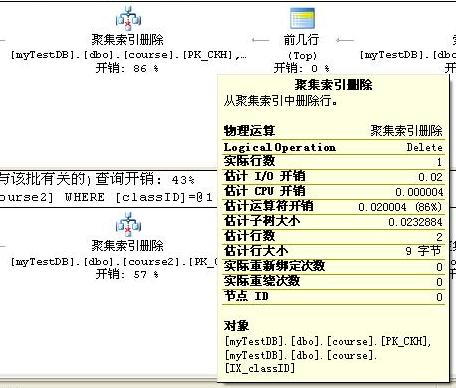
分析区别二的原因:我们来看下聚集索引删除的具体内容,下面是在条件列classID上创建了非聚集索引的表course表在发生删除时的执行计划图,它在删除后需要维护索引PK_classID,占用部分的系统开销。而没有创建索引的表course2由于没有索引维护的额外开销,所以反而占优势。
第二步:分别给两个表插入相当的数据10000行,然后删除第5000条记录。
区别同第一步。难道我的观点真的正确?
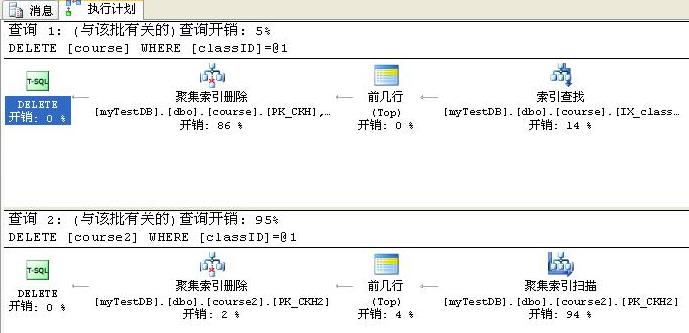
第三步:分别给两个表插入相当的数据100000行,然后删除第50000条记录。执行计划图如下:
区别一:同前两步的区别一。
区别二:系统开销不同,此时会发现创建了索引的course表在开销上占5%,而没有创建索引的course2表占了95%,这可是10倍的区别啊。
第四步:分别给两个表插入相当的数据1000000行,然后删除第500000条记录。
区别同第三步。
总结:当删除语句的条件列没有创建索引时分两种情况:
第一:数据量较小,我测试时在10000以下,此时两者的差别不大,反而会因为创建了索引而引起磁盘开销。开销差距不大是因为数据量小时,即使全表扫描速度也不慢,此时索引的优势并不明显。
第二:数据量较大,我测试时在100000以上,此时两者的差别较大。条件列创建了索引的表明显效率高。
第三:归根结底,系统的主要开销还是在删除的第一步,查找数据行上。能更快查找到删除行的方案效率最高。
事由:今天在博客园北京俱乐部MSN群中和网友讨论了关于索引对delete的影响问题,事后感觉非常汗颜,因为我的随口导致错误连篇。大致话题是这样的,并非原话:
[讨论:] delete course where classID=500001 classID上没有创建任何索引,为了提高删除效率,如果在classID上创建一个非聚集索引会不会提高删除的效率呢?
我当时的观点:不能。
我当时的理由:数据库在执行删除时,如果在classID上创建了非聚集索引,首先按这个非聚集索引查找数据,找到索引行后,根据索引行后面带的聚集索引地址最后找到真正的物理数据行,并且执行删除,这个过程看起来没有作用,只能创建聚集索引来提高删除效率,因为如果classID是聚集索引,那么直接聚集索引删除,此时的效率最高。
下班后对这个话题再次想了下,觉的自己的观点都自相矛盾,既然知道删除时,会在条件列上试图应用已经存在的索引,那么为什么创建非聚集索引会无效呢?如果表的数据相当大,classID上如果没有任何索引,查找数据时就要执行表扫描,而表扫描的速度是相当慢的,为此为了证明下这个问题,我特意做了一个示意性的实验。
创建两个表course 和course2,创建语句如下,它们唯一的区别就在于索引,course表中classID上创建了非聚集索引,而course2上没有创建任何索引。
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
--创建索引
create index IX_classID
on course(classID)
CREATE TABLE [dbo].[course2](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH2] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
实验过程:
第一步:分别给两个表插入相当的数据1000行,然后删除第500条记录。
delete course
where classID=500
delete course2
where classID=500
执行计划图如下:我们可以看到在执行删除时,数据库分为三部分:
1:查找到要删除的数据行;
2:包含一个top操作。
3:执行聚集索引删除。
区别一:由于course表的classID上创建了索引,所以查找时按PK_classID来查找,course2表的classID由于没有任何的索引,为了查找到要删除的数据行,就只能按聚集索引查找,此时实际上是全表扫描。
区别二:系统开销不同,让人意外的是,结果表明好像白天的观点是正确的,创建了索引的coure表在开销上比没有创建索引的course2还大一点。
分析区别二的原因:我们来看下聚集索引删除的具体内容,下面是在条件列classID上创建了非聚集索引的表course表在发生删除时的执行计划图,它在删除后需要维护索引PK_classID,占用部分的系统开销。而没有创建索引的表course2由于没有索引维护的额外开销,所以反而占优势。
第二步:分别给两个表插入相当的数据10000行,然后删除第5000条记录。
区别同第一步。难道我的观点真的正确?
第三步:分别给两个表插入相当的数据100000行,然后删除第50000条记录。执行计划图如下:
区别一:同前两步的区别一。
区别二:系统开销不同,此时会发现创建了索引的course表在开销上占5%,而没有创建索引的course2表占了95%,这可是10倍的区别啊。
第四步:分别给两个表插入相当的数据1000000行,然后删除第500000条记录。
区别同第三步。
总结:当删除语句的条件列没有创建索引时分两种情况:
第一:数据量较小,我测试时在10000以下,此时两者的差别不大,反而会因为创建了索引而引起磁盘开销。开销差距不大是因为数据量小时,即使全表扫描速度也不慢,此时索引的优势并不明显。
第二:数据量较大,我测试时在100000以上,此时两者的差别较大。条件列创建了索引的表明显效率高。
第三:归根结底,系统的主要开销还是在删除的第一步,查找数据行上。能更快查找到删除行的方案效率最高。

相关文章推荐
- SQL开发中容易忽视的一些小地方(二)
- SQL开发中容易忽视的一些小地方(二)
- SQL开发中容易忽视的一些小地方( 三)
- SQL开发中容易忽视的一些小地方( 三)
- SQL开发中容易忽视的一些小地方(二)
- SQL开发中容易忽视的一些小地方(一)
- SQL开发中容易忽视的一些小地方(四)
- SQL开发中容易忽视的一些小地方(四)
- SQL开发中容易忽视的一些小地方(一)
- SQL开发中容易忽视的一些小地方(五)
- SQL开发中容易忽视的一些小地方(zz)
- SQL开发中容易忽视的一些小地方(五)
- SQL开发中容易忽视的一些小地方(五)
- SQL开发中容易忽视的一些小地方
- SQL开发中容易忽视的一些小地方(四)
- SQL开发中容易忽视的一些小地方(六)
- SQL开发中容易忽视的一些小地方(二)
- SQL开发中容易忽视的一些小地方(一)【null的用法及注意事项】
- SQL开发中容易忽视的一些小地方
- SQL开发中容易忽视的一些小地方(一)