The second generation: Intel's EPT and AMD's NPT
2008-12-25 13:25
411 查看
As we discussed in "memory
management", managing the virtual memory of the different guest OS and translating
this into physical pages can be extremely CPU intensive.
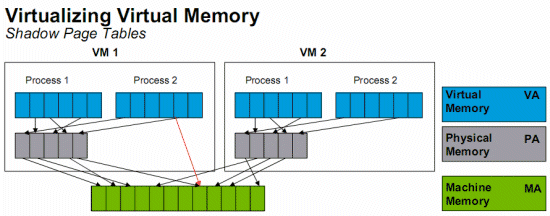
Without shadow
pages we would have to translate virtual memory (blue) into "guest OS physical
memory" (gray) and then translate the latter into the real physical memory
(green). Luckily, the "shadow page table" trick avoids the double bookkeeping
by making the MMU work with a virtual memory (of the guest OS, blue) to real physical
memory (green) page table, effectively skipping the intermediate "guest OS
physical memory" step. There is catch though: each update of the guest OS page
tables requires some "shadow page table" bookkeeping. This is rather bad
for the performance of software-based virtualization solutions (BT and Para) but
wreaks havoc on the performance of the early hardware virtualization solutions.
The reason is that you get a lot of those ultra heavy VMexit and VMentry calls.
The second generation
of hardware virtualization, AMD's nested paging and Intel's EPT technology partly
solve this problem by brute hardware force.
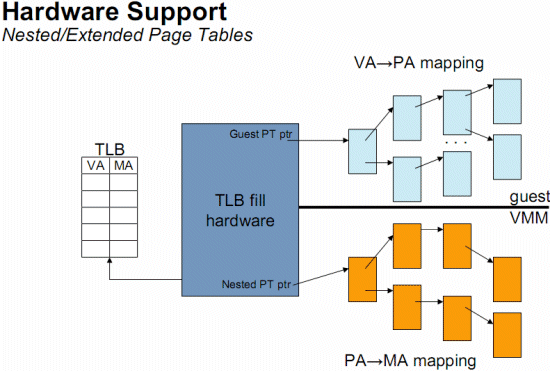
EPT or Nested Page
Tables is based on a "super" TLB that keeps track of both the Guest
OS and the VMM memory management.
As you can see
in the picture above, a CPU with hardware support for nested paging caches both
the Virtual memory (Guest OS) to Physical memory (Guest OS) as the Physical Memory
(Guest OS) to real physical memory transition in the TLB. The TLB has a new VM specific
tag, called the Address Space IDentifier (ASID). This allows the TLB to keep track
of which TLB entry belongs to which VM. The result is that a VM switch does not
flush the TLB. The TLB entries of the different virtual machines

all coexist peacefully
in the TLB… provided the TLB is big enough of course!
This makes
the VMM a lot simpler and completely annihilates the need to update the shadow
page tables constantly. If we consider that the Hypervisor has to intervene for
each update of the shadow page tables (one per VM running), it is clear that nested
paging can seriously improve performance (up to 23% according to AMD). Nested paging
is especially important if you have more than one (virtual) CPU per VM. Multiple
CPUs have to sync the page tables often, and as a result the shadow page tables
have to update a lot more too. The performance penalty of shadow page tables gets
worse as you use more (virtual) CPUs per VM. With nested paging, the CPUs
simply synchronize TLBs as they would have done in a non-virtualized
environment.
There is only
one downside: nested paging or EPT makes the virtual to real physical address translation
a lot more complex if the TLB does not have the right entry. For each step we take
in the blue area, we need to do all the steps in the orange area. Thus, four
table searches in the "native situation" have become 16 searches (for
each of the four blue steps, four orange steps).
In order to
compensate, a CPU needs much larger TLBs than before, and TLB misses are now
extremely costly. If a TLB miss happens in a native (non-virtualized) situation,
we have to do four searches in the main memory. A TLB miss then results in a performance
hit. Now look at the "virtualized OS with nested paging" TLB miss situation:
we have to perform 16 (!) searches in tables located in the high latency system
RAM. Our performance hit becomes a performance catastrophe! Fortunately, only a
few applications will cause a lot of TLB misses if the TLBs are rather large.
management", managing the virtual memory of the different guest OS and translating
this into physical pages can be extremely CPU intensive.
Without shadow
pages we would have to translate virtual memory (blue) into "guest OS physical
memory" (gray) and then translate the latter into the real physical memory
(green). Luckily, the "shadow page table" trick avoids the double bookkeeping
by making the MMU work with a virtual memory (of the guest OS, blue) to real physical
memory (green) page table, effectively skipping the intermediate "guest OS
physical memory" step. There is catch though: each update of the guest OS page
tables requires some "shadow page table" bookkeeping. This is rather bad
for the performance of software-based virtualization solutions (BT and Para) but
wreaks havoc on the performance of the early hardware virtualization solutions.
The reason is that you get a lot of those ultra heavy VMexit and VMentry calls.
The second generation
of hardware virtualization, AMD's nested paging and Intel's EPT technology partly
solve this problem by brute hardware force.
EPT or Nested Page
Tables is based on a "super" TLB that keeps track of both the Guest
OS and the VMM memory management.
As you can see
in the picture above, a CPU with hardware support for nested paging caches both
the Virtual memory (Guest OS) to Physical memory (Guest OS) as the Physical Memory
(Guest OS) to real physical memory transition in the TLB. The TLB has a new VM specific
tag, called the Address Space IDentifier (ASID). This allows the TLB to keep track
of which TLB entry belongs to which VM. The result is that a VM switch does not
flush the TLB. The TLB entries of the different virtual machines
all coexist peacefully
in the TLB… provided the TLB is big enough of course!
This makes
the VMM a lot simpler and completely annihilates the need to update the shadow
page tables constantly. If we consider that the Hypervisor has to intervene for
each update of the shadow page tables (one per VM running), it is clear that nested
paging can seriously improve performance (up to 23% according to AMD). Nested paging
is especially important if you have more than one (virtual) CPU per VM. Multiple
CPUs have to sync the page tables often, and as a result the shadow page tables
have to update a lot more too. The performance penalty of shadow page tables gets
worse as you use more (virtual) CPUs per VM. With nested paging, the CPUs
simply synchronize TLBs as they would have done in a non-virtualized
environment.
There is only
one downside: nested paging or EPT makes the virtual to real physical address translation
a lot more complex if the TLB does not have the right entry. For each step we take
in the blue area, we need to do all the steps in the orange area. Thus, four
table searches in the "native situation" have become 16 searches (for
each of the four blue steps, four orange steps).
In order to
compensate, a CPU needs much larger TLBs than before, and TLB misses are now
extremely costly. If a TLB miss happens in a native (non-virtualized) situation,
we have to do four searches in the main memory. A TLB miss then results in a performance
hit. Now look at the "virtualized OS with nested paging" TLB miss situation:
we have to perform 16 (!) searches in tables located in the high latency system
RAM. Our performance hit becomes a performance catastrophe! Fortunately, only a
few applications will cause a lot of TLB misses if the TLBs are rather large.

相关文章推荐
- [转贴]虚拟化时记忆体管理:AMD NPT/Intel EPT简介--转自沈洁转自某港澳台同胞
- The pros and "conns" of Intel's ConnMan for Linux
- Intel® 64 and IA-32 Architectures Software Developer's Manuals
- intel 64 and IA-32 Archtectures Software Developer's Manual 笔记
- Best Practices for Paravirtualization Enhancements from Intel® Virtualization Technology: EPT and VT-d
- Intel's Processing RMS (Recognition, Mining and Synthesis)
- Software stack checking and 'attribute conflict'
- 错误整理:No plugin found for prefix 'jetty' in the current project and in the plugin groups
- The Relation between `skb->len' and `skb->data_len' and What They Represent
- 223.I can't be your friend and your flatterer too. 朋友不能阿谀奉承
- Can't load AMD 64-bit .dll on a IA 32-bit platform
- Busy Developers' Guide to HSSF and XSSF Features
- [zt] What do 'statically linked' and 'dynamically linked' mean?
- ADB not responding. You can wait more,or kill"abd.exe" process manually and click 'Restar
- What do 'statically linked' and 'dynamically linked' mean?
- C++ difference of keywords 'typename' and 'class' in templates
- UVA 1484 - Alice and Bob's Trip(树形DP)
- armasm: Use of MRS and MSR instructions ('Deprecated form of PSR field specifier')
- UVA 10018 and UVA 701 's reports.
- About the difference of href='javascript:void(0)' and href=‘#’