北京西直门地铁
2006-11-28 11:06
399 查看
smp_affinity值计算:
在前阵子看到HelloDB的一篇文章“MySQL单机多实例方案”中提到:
因为单机运行多个实例,必须对网络进行优化,我们通过多个的IP的方式,将多个MySQL实例绑定在不同的网卡上,从而提高整体的网络能力。还有一种更高级的做法是,将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率。
于是,对“将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率”比较感兴趣,所以找了点资料了解一下。先总结如下:
1. 不同的设备一般都有自己的IRQ号码(当然一个设备还有可能有多个IRQ号码)
通过命令:cat /proc/interrupts查看
如:cat /proc/interrupts | grep -e “CPU\|eth4″
#当使用KVM中的device assignment特性时,在/proc/interrupts中,有“ … IR-PCI-MSI-edge kvm:0000:05:00.1 …”这样的行。
2. 中断的smp affinity在cat /proc/irq/$Num/smp_affinity
可以echo “$bitmask” > /proc/irq/$num/smp_affinity来改变它的值。
如: echo 8 > /proc/irq/93/smp_affinity #表示将93号irq绑定到#3号CPU
echo 400 > /proc/irq/93/smp_affinity #表示将93号irq绑定到#10号CPU(我们可以用工具将16进制400转换为二进制为10000000000)
注意smp_affinity这个值是一个十六进制的bitmask,它和cpu No.序列的“与”运算结果就是将affinity设置在那个(那些)CPU了。(也即smp_affinity中被设置为1的位为CPU No.)
比如:我有8个逻辑core,那么CPU#的序列为11111111 (从右到左依次为#0~#7的CPU)
如果cat /proc/irq/84/smp_affinity的值为:20(二进制为:00100000),则84这个IRQ的亲和性为#5号CPU。
每个IRQ的默认的smp affinity在这里:cat /proc/irq/default_smp_affinity
另外,cat /proc/irq/$Num/smp_affinity_list 得到的即是irq绑定的CPU的一个List。
3. 默认情况下,有一个irqbalance在对IRQ进行负载均衡,它是/etc/init.d/irqbalance
在某些特殊场景下,可以根据需要停止这个daemon进程。
4. 如果要想提高性能,将IRQ绑定到某个CPU,那么最好在系统启动时,将那个CPU隔离起来,不被scheduler通常的调度。
可以通过在Linux kernel中加入启动参数:isolcpus=cpu-list来将一些CPU隔离起来。
参考:http://smilejay.com/2012/02/irq_affinity/
http://blog.yufeng.info/archives/2037 *****MYSQL数据库网卡软中断不平衡问题及解决方案
LVS网卡软中断配置这是之前做LVS的网卡软中断配置时整理的一个文档,网上的资料不是很全,将配置方法share给大家。
为什么要配置网卡软中断,主要是因为在网络非常 heavy 的情况下,对于文件服务器、高流量 Web 服务器这样的应用来说,把不同的网卡 IRQ 均衡绑定到不同的 CPU 上将会减轻某个 CPU 的负担,提高多个 CPU 整体处理中断的能力。合理的根据自己的生产环境和应用的特点来平衡 IRQ 中断有助于提高系统的整体吞吐能力和性能。
先看下未升级之前的效果:可以看到网卡软中断被分配到了两个指定的CPU核心上(看%si列):

经过升级内核调整参数后的效果:

软中断被均匀的分配到8个核心上,下面来说下具体过程
首先,将内核升级到2.6.32以上,升级过程略去:
为什么要将2.6.18内核升级到2.6.32?
这个主要是因为2.6.18还丌支持RPS这个特性
那什么是rps呢?具体可以参看: http://lwn.net/Articles/328339/ http://lwn.net/Articles/378617/
为什么要将2.6.18内核升级到2.6.32?
这个主要是因为2.6.18不支持RPS这个特性
那什么是rps呢?具体可以参看: http://lwn.net/Articles/328339/ http://lwn.net/Articles/378617/
第二步:
如果你的服务器网卡和我一样是Broadcom的,那么你就得做这一步,不是请跳到第三步(待deven确认)

在/etc/modprobe.conf加上下面这行: options bnx2 disable_msi=1
改完这个重新加载下网卡模块modprobe -r bnx2;modprobe bnx2或者重新启动服务器。
redhat 6.1或以上版本系统,没有“/etc/modprobe.conf”这个文件,需要编辑“/etc/modprobe.d/dist.conf”。重新加载网卡后可以用“modprobe -c|grep bnx2”查看配置有没有生效
为什么要加这个?
这个主要是因为broadcom网卡开启msi后,会造成后面的修改smp_affinity丌生效,intel的网卡没这个问题。
msi是什么?下面的链接有解析: http://lwn.net/Articles/44139/ 第三步:
停用irqbalance
/etc/init.d/irqbalance stop
这个是一个自动调整中断的工具,有兴趣的可以看下irqbalance的官方网站: http://irqbalance.org/ 第四步:
设置eth0、eth1对应中断号的 smp_affinity 为 “ff”
先看一下网卡的中断号:

从图中可以看到网卡eth1的中断号为16,eth0的中断号为18
将/proc/irq/中断号/smp_affinity修改为ff,修改完成后就可以开启lvs了,现在中断应该均分到各个核心上了。
smp_affinity这个参数是怎么得来的? 可参考下面链接:
http://www.cs.uwaterloo.ca/~brecht/servers/apic/SMP-affinity.txt
这个也可以看看: http://www.cnblogs.com/Bozh/archive/2013/01/17/2864201.html
http://www.docin.com/p-289489132.html (盛大的)
以下这篇文章转自:http://hi.baidu.com/excalibur/item/77122ebeb0544242bb0e1236
消耗CPU资源的是ksoftirqd进程,全部用于处理软中断(从进程名也能识别出了)。
搜了一下,很多人都遇到这类问题,似乎也没有解决。了解到并尝试过的解决方案有:
1、减少集群成员的数量;
2、修改集群模式(NAT、TURNL、DR);
3、修改集群调度算法;
4、升级操作系统内核到2.6.20以上;
5、调整网卡的最大传输单元(MTU);
6、修改设备中断方式;
7、使用多网卡负载均衡;
8、升级硬件(网卡);
9、更换操作系统。
一一解说如下吧:
第1点:减少集群成员的数量。由于瓶颈不在真实服务器上,所以减少成员数量,lvs性能没有明显变化。
第2点:修改集群模式。理论上DR模式是最省资源的,大概了解理论的朋友应该都知道。由于NAT模式不满足需求,故仅对比了DR和TUN模式,两者没有明显区别。
第3点:修改集群调度算法。已有的十种算法中属rr最简单,而且目前瓶颈还未深入到这一层。实际上在处理网络包的时候导致的瓶颈。调度算法简单比较了rr和wrr,两者没有明显区别。
第4点:升级操作系统内核到2.6.20以上。我直接升级到当前已发布的最新版本2.6.34,结果瓶颈并没有得到改善。

第5点:调整网卡的最大传输单元。交换机支持最大的传输单元是9216,将网卡的最大传输单元分别修改为:1500(默认)、5000、9000、9216。其中1500和5000两者没有明显差别,9000和9216会导致网络不稳定,性能也没有提高反而出现大量连接超时。
第6点:修改设备中断方式。通过修改设置中断/proc/irq/${网卡中断号}/smp_affinity:
测试服务器CPU为四核,理论上网卡的smp_affinity值为1、2、4、8分别对应cpu0、cpu1、cpu2、cpu3。
结果:
1、网卡的smp_affinity默认值为8,测试过程中软中断全部由cpu3处理。正确
2、设置smp_affinity = 1,测试过程中软中断全部由cpu0处理。正确
3、设置smp_affinity = 2,测试过程中软中断全部由cpu1处理。正确
4、设置smp_affinity = 4,测试过程中软中断全部由cpu2处理。正确
5、设置smp_affinity = 5,测试过程中软中断全部由cpu0处理,预期应该分配给cpu0和cpu2处理。无效
6、设置smp_affinity = f,测试过程中软中断全部由cpu0处理,预期应该分配给cpu0、cpu1、cpu2和cpu2处理。无效(经过Deven验证,的确如此)
即:修改smp_affinity的功能只针对单核有效。(Deven:按照我的理解,应该是说设置smp_affinity只能绑定到一个cpu核,绑定多核是不生效的,如果作者把有多个网卡中断号的网卡绑定到不同cpu应该是可行,他说不可行,应该是他的网卡为非多队列)
第7点:使用多网卡负载均衡。此方案可行!使用两张网卡绑定一个IP地址,性能就提升了一倍,效果非常明显。原因就是两张网卡各用一个CPU核,相比用单核而言,性能自然提升一倍。

配置方式如下:
单网卡工作模式
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROTO=none
BROADCAST=192.168.223.255
HWADDR=00:1E:90:76:6F:E0
IPADDR=192.168.223.113
NETMASK=255.255.254.0
NETWORK=10.20.222.0
ONBOOT=yes
GATEWAY=192.168.222.1
TYPE=Ethernet
绑定双网卡操作步骤
echo 'alias bond0 bonding' >> /etc/modprobe.conf
# cat /etc/sysconfig/network-scripts/ifcfg-bond0
DEVICE=bond0
BOOTPROTO=static
BROADCAST=192.168.223.255
MACDDR=00:1E:90:76:6F:E2
IPADDR=192.168.223.113
NETMASK=255.255.254.0
NETWORK=192.168.222.0
USERCTL=no
ONBOOT=yes
GATEWAY=10.20.222.1
TYPE=Ethernet
BONDING_OPTS="mode=0 miimon=100"
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ERCTL=no
ONBOOT=yes
MASTER=bond0
SLAVE=yes
BOOTPROTO=none
# cat /etc/sysconfig/network-scripts/ifcfg-eth1
DEVICE=eth1
USERCTL=no
ONBOOT=yes
MASTER=bond0
SLAVE=yes
BOOTPROTO=none
# service network restart

[b]第8点,升级硬件,使用支持RSS功能的网卡。 [/b]
下面是intel对RSS的说明
Receive-side scaling (RSS) routes incoming packets to specific queues, efficiently balancing network loads across CPU cores and increasing performance on multi-processor systems. RSS, called Scalable I/O in Linux*, creates a hash table from IP, TCP, and Port Addresses and uses that table to decide which queue to route a packet to, and to which processor the packet should be associated.
可是从我们使用网卡的官网硬件指标上,都是支持RSS的。Windows的设置方式是`[b]netsh int tcp set global rss=enabled`。 [/b]
第9点,更换操作系统。此方案在生产环境下部署的可能性比较小,但是否关操作系统的事确实需要确认。
据说Windows的NLB、solaris、AIX支持网卡RSS,目前还有待确认。
我的blog前面有一篇文章描述了软终端导致单cpu消耗100%,导致机器丢包跟延迟高的问题,文中我只是简单的说明了一下升级内核进行解决的,这个问题我并没有进行一个问题解决的说明,经历了一系列的调整后,单机的并发从单机单网卡承受100M流量到160M流量,到现在的最高的230M流量,在程序没有大规模修改的情况下效果还是十分的明显,这次这篇文章将完整的说一下我的一个解决方法:
先说说我的场景,我目前负责的一个项目,大量的小数据包,长连接,每个数据包都不大,大概10Kbit左右一个包,但是数量十分之大,目前在生产环境中最大的数据包数量高达15W/s的数量,常见的网游系统,小图片cdn系统,这些服务类型都算是这种类型,单网卡流量不大,但是数据包数量极大,我目前调优的结果是
在Xeon E5504, BCM5716的网卡,8G的dell r410的机器,单网卡实现了230MBits大的流量,系统的load为0,8颗cpu每一颗还有10%左右的IDLE,由于我们的系统是数据包的转发,还有一个网卡同期的流量使220M,12.8W的数据包,算上总数,大概可以到450MBits的流量,25.5W的小包,由于人数有限,流量没有跑上去,预计可以跑到480MBits的流量,生产环境的一台机器的数据:
流量及机器的网卡包数量

机器的cpu消耗

首先机器的选型,由于大量小包的cpu密集的系统,当然cpu越性能越高越好咯,但是成本相应的高。对于这种类型的机器,网卡选型也是十分的重要,一定要选择支持msi-x的网卡类型,什么是msi-x大家可以查询google资料去了解一下,目前市面出售的大部分最新的网卡都有这个功能,查看方法lspci -v,看到如下图的内容

再者网卡是否支持多队列,多队列网卡十分的重要,不是多队列的网卡,这篇文章几乎不需要看了,可以直接忽略掉,查看方法cat /proc/interrupts,这个方法并不适用所有的操作系统例如在rhel 5.5的os当中,bcm5716的网卡就看不到,具体我也没有查到怎么查看的方法,麻烦知道的用户告知一声,如果是的话应该可以看到如下图的内容

每一个网卡有8个队列,对于这种大量小包的cpu密集型的系统,多队列的网卡性能至少***能50%以上,我们生产环境的有台非多队列的Intel 82574的网卡调优后只能跑到160M左右流量,跟上图明显的一个对比.而同等情况下买一个多队列的网卡明显要便宜很多。
操作系统的选择,目前大部分企业使用的是rhel系列的os,包括标准的rhel跟centos作为一个生产环境的os,目前主力的版本还是rhel 5系列的os,而rhel 5系列的内核版本对于软中断处理并不是很好,调优的结果不是很理想,在rhel 5系列的os上,我们最高流量单网卡也就是160M左右,而且机器的load也很高了,机器已经出现小量的丢包,而且只是使用了4到6个cpu还有几个cpu没有利用上,机器性能没有挖掘完毕,由于我们的机器没有存储的压力,单纯的只是消耗cpu资源,没有io的压力,于是大胆的启用刚出的rhel 6.1的系统,看重这个系统的原因是,该os的内核已经加入了google的两个原本在2.6.35当中才启用的2个补丁――RPS/RFS,RPS主要是把软中断的负载均衡到各个cpu,由于RPS只是单纯把数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对于cpu cache的影响会很大,那么RFS确保应用程序处理的cpu跟软中断处理的cpu是同一个,这样就充分利用cpu的cache,默认情况下,这个功能并没有开启,需要手动开启开启方法,开启的前提是多队列网卡才有效果。
echo ff > /sys/class/net/<interface>/queues/rx-<number>/rps_cpus
echo 4096 > /sys/class/net/<interface>/queues/rx-<number>/rps_flow_cnt
echo 30976 > /proc/sys/net/core/rps_sock_flow_entries(经过Deven在虚拟机测试,centos6.4版本,设置上面3个选项就搞定了)
对于2个物理cpu,8核的机器为ff,具体计算方法是第一颗cpu是00000001,第二个cpu是00000010,第3个cpu是00000100,依次类推,由于是所有的cpu都负担,所以所有的cpu数值相加,得到的数值为11111111,十六进制就刚好是ff。而对于/proc/sys/net/core/rps_sock_flow_entries的数值是根据你的网卡多少个通道,计算得出的数据,例如你是8通道的网卡,那么1个网卡,每个通道设置4096的数值,8*4096就是/proc/sys/net/core/rps_sock_flow_entries的数值,对于内存大的机器可以适当调大rps_flow_cnt,这个时候基本可以把软中断均衡到各个cpu上了,而对于cpu的使用,还有其它的例如use,sys等,这个不均衡的话,cpu还是会浪费掉,同时对我们的程序针对多cpu进行小部分的开发跟重新编译,本身我们程序就是多进程的一个模型,我们采用nginx的进程管理模型,一个master管理work进程,master分配每一个连接给work进程,由work进程处理用户的请求,这样每一个进程都能均衡负担几乎相同的处理请求,同时在6.1的系统中gcc新增一个openmp的指令,这个指令作用针对多核,增加程序的并行计算的功能,不需要大规模的更改代码就能实现多核的并行性计算,具体使用使用方法请见如下urlhttp://zh.wikipedia.org/zh/OpenMP针对上面的处理,基本上可以实现cpu按理说可以实现完全的均衡了,但是当我们在实际的使用过程中发现还是cpu还不是100%的均衡,存在1到2个cpu消耗量还是比其它的要大20%左右,导致在高峰期有1到2个cpu的idle使用完毕,导致用户使用存在卡的情况,这个时候,需要手动调节一下cpu的使用情况,在这操作之前先了解几个名词以及其作用
一个是IO-APIC(输入输出装置的高级可编程中断控制器)
为了充分挖掘 SMP 体系结构的并行性,能够把中断传递给系统中的每个CPU至关重要,基于此理由,Intel 引入了一种名为 I/O-APIC的东西。该组件包含两大组成部分:一是“本地 APIC”,主要负责传递中断信号到指定的处理器;举例来说,一台具有三个处理器的机器,则它必须相对的要有三个本地 APIC。另外一个重要的部分是 I/O APIC,主要是收集来自 I/O 装置的 Interrupt 信号且在当那些装置需要中断时发送信号到本地 APIC。这样就能充分利用多cpu的并行性。如果用户对于IO-APIC更感兴趣,请见如下url的中的pdf的说明http://wenku.baidu.com/view/ccdc114e2e3f5727a5e962e9.html另外一个就是irqbalance
irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode.处于 Performance mode时irqbalance 会将中断尽可能均匀地分发给各个CPU以充分利用 CPU 多核,提升性能.处于 Power-save mode时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗
通过这我们就发现我们是一个非常繁重的系统,并没有节能的需求,而是需要充分利用各个cpu的性能,而事实上在一个大量小包的系统上,irqbalance优化几乎没有效果,而且还使得cpu消耗不均衡,导致机器性能得不到充分的利用,这个时候需要把它给结束掉
/etc/init.d/irqbalance stophttp://blog.yufeng.info/archives/2422 ****深度剖析告诉你irqbalance有用吗?同时,手动绑定软中断到指定的cpu,对于一个8个队列的网卡,8核的机器,可以指定一个cpu处理一个网卡队列的中断请求,并根据cpu的消耗情况,手动调整单个网卡的队列到资源消耗低的cpu上,实现手动均衡,具体操作方法,执行如下命令
cat /proc/interrupts

计算cpu的方法第一颗为00000001换算成16进制为1,第2颗cpu为00000010换算成16进制为2,依次类推得出,第8颗cpu为80,这样就可以做如下的绑定了
echo 0001 > /proc/irq/<number>/smp_affinity
这样就可以绑定中断到指定的cpu了,这个时候有可能会问,我的机器是一个2通道的网卡,这个时候如果一个通道一个cpu绑定,这个时候就浪费了6颗cpu了,还是达不到完全均衡负载,为什么不能像前面rps那样,
echo ff > /proc/irq/<number>/smp_affinity
设置一个ff达到所有的cpu一起均衡呢,这个因为io-apic工作的2个模式logical/low priority跟fixed/physical模式,这两个模式的区别在于,前面一个模式能够把网卡中断传递给多核cpu进行处理,后一种模式对应一个网卡队列的中断只能传递给单cpu进行处理,而linux是fixed/physical工作模式,如果你设置上面那个选项,只能第一个cpu进行软中断的处理,又回到未优化前了。那么为什么不开启logical/low priority呢,当一个tcp连接发起,当数据包到底网卡,网卡触发中断,中断请求到其中一个cpu,而logical/lowpriority并不能保证后续的数据包跟前面的包处于同一个cpu,这样后面的数据包发过来,又可能处于另外一个cpu,这个时候同一个socket都得检查自己的cpu的cache,这样就有可能部分cpu取不到数据,因为本身它的cache并没用数据,这个时候就多了多次的cpu的查找,不能充分利用cpu的效率。对于部分机器来说并不能开启logical/low priority模式,一种可能是cpu过多,另外一种是bios不支持。因此对于那种单队列网卡并不能充分发挥cpu的性能。
经过上述的调整基本可以达到几乎完全均衡的效果,每个cpu都能发挥他的效果。也几乎可以到达我调优的效果
对于一个完整的系统来说,不仅有数据包发送的需求还有数据接收的请求,而rps/rfs主要解决数据接收的一个中断均衡的问题,rps/rfs的作者提交了一个xps(Transmit Packet Steering), 这个patch主要是针对多队列的网卡发送时的优化,当发送一个数据包的时候,它会根据cpu来选择对应的队列,目前这个patch已经添加在2.6.38内核版本当中,我们已经在生产环境中,部分机器上已经使用上了,据作者的benchmark,能够提高20%的性能,具体使用方法
echo ff > /sys/class/net/<interface>/queues/tx-<number>/xps_cpus
由于还是新上的系统,还没敢大规模放用户进来,还在测试系统的稳定性,不知道上限具体能到多少,从当前生产环境跑的流量来看,比同等其它的机器,cpu消耗情况,确实要减少一些,流量没有跑上来,效果不是特别的明显,还有待继续测试,得出一个具体的结果。
另外对于intel的网卡的用户,intel有个叫ioat的功能,关于ioat功能大家可以网上查查资料.
而对于centos的用户来说,目前还只是出了6.0的版本,并没有上述功能,要大规模的推广,建议大家编译2.6.38的内核版本,因为2.6.38的版本已经包含了上述几个补丁。编译内核生成内核的rpm包,能快速的在同一批机器上快速部署上去。
以上就是我的对cpu密集型系统的一个优化过程,欢迎大家来讨论。
昨天在查LVS调度均衡性问题时,最终确定是 persistence_timeout 参数会使用IP哈希。目的是为了保证长连接,即一定时间内访问到的是同一台机器。而我们内部系统,由于出口IP相对单一,所以总会被哈希到相同的RealServer。
随后和 @吴佳明_普空八卦LVS压力大的问题,他推荐我使用RPS。小搜一下,瞬间发现这真是个宝贝!
过去使用LVS,遇到过单核CPU被软中断耗尽的问题,然后知道了网卡驱动与多队列。而后知道了淘宝对LVS的优化,然后对生产环境进行了优化,效果显著。
如今单台LVS带宽吃到近500Mb/s,每秒进出包都过40万。此时发现网卡(4队列)对应CPU的软中断消耗已过40%了,倍感压力。按理,空闲CPU如果少于40%,则要新增节点了。关于中断不均衡的问题,听取了普空的意见,效果也非常明显,全均衡了:

原来CentOS 6.1就开始支持RPS了,原生支持需要使用Linux内核2.6.38或以上版本。
简单来讲,RPS就是让网卡使用多核CPU的。传统方法就是网卡多队列(RSS,需要硬件和驱动支持),RPS则是在系统层实现了分发和均衡。献上修改设置的脚本一例:
分享igi同学对: 网卡多队列、网卡RPS支持的详细解释和测试数据!
http://bbs.chinaunix.net/forum.php?mod=viewthread&action=printable&tid=1927269
多队列网卡简介
http://blog.csdn.net/turkeyzhou/article/details/7528182
多队列网卡是一种技术,最初是用来解决网络IO QoS (quality of service)问题的,后来随着网络IO的带宽的不断提升,单核CPU不能完全处满足网卡的需求,通过多队列网卡驱动的支持,将各个队列通过中断绑定到不同的核上,以满足网卡的需求。常见的有Intel的82575、82576,Boardcom的57711等,下面以公司的服务器使用较多的Intel 82575网卡为例,分析一下多队列网卡的硬件的实现以及linux内核软件的支持。

图1.1 82575硬件逻辑图

图2.1 2.6.21之前内核协议栈

图2.2 2.6.21之前net_device
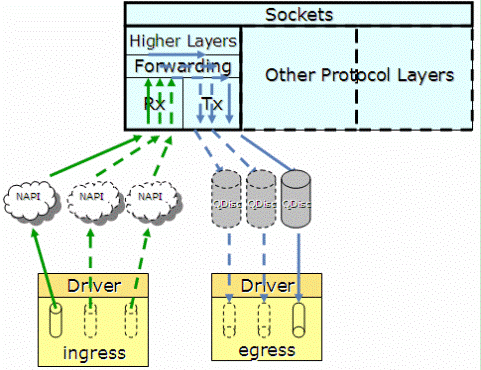
图3.1 2.6.21之后内核协议栈

图3.2 2.6.21之后net_device

图4.1 /proc/interrupts

图5.1 不合理中断绑定linux network子系统的负责人David Miller提供了一个脚本,首先检索/proc/interrupts文件中的信息,按照图4.1中eth0-rx-0($VEC)中的VEC得出中断MASK,并将MASK写入中断号53对应的smp_affinity中。由于eth-rx-0与eth-tx-0的VEC相同,实现同一个queue的tx与rx中断绑定到一个核上,如图4.3所示。

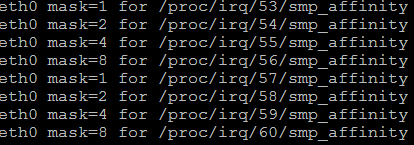
图4.2 set_irq_affinity

图4.3 合理的中断绑定
set_irq_affinity脚本位于http://mirror.oa.com/tlinux/tools/set_irq_affinity.sh。
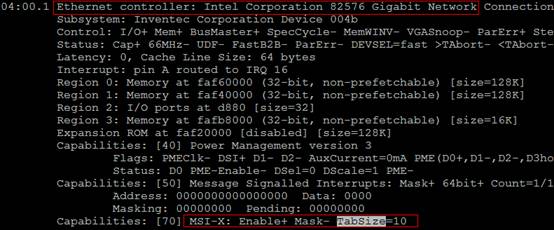
图4.4 lspci内容Message Signaled Interrupts(MSI)是PCI规范的一个实现,可以突破CPU 256条interrupt的限制,使每个设备具有多个中断线变成可能,多队列网卡驱动给每个queue申请了MSI。MSI-X是MSI数组,Enable+指使能,TabSize是数组大小。
随后和 @吴佳明_普空八卦LVS压力大的问题,他推荐我使用RPS。小搜一下,瞬间发现这真是个宝贝!
过去使用LVS,遇到过单核CPU被软中断耗尽的问题,然后知道了网卡驱动与多队列。而后知道了淘宝对LVS的优化,然后对生产环境进行了优化,效果显著。
如今单台LVS带宽吃到近500Mb/s,每秒进出包都过40万。此时发现网卡(4队列)对应CPU的软中断消耗已过40%了,倍感压力。按理,空闲CPU如果少于40%,则要新增节点了。关于中断不均衡的问题,听取了普空的意见,效果也非常明显,全均衡了:
原来CentOS 6.1就开始支持RPS了,原生支持需要使用Linux内核2.6.38或以上版本。
简单来讲,RPS就是让网卡使用多核CPU的。传统方法就是网卡多队列(RSS,需要硬件和驱动支持),RPS则是在系统层实现了分发和均衡。献上修改设置的脚本一例:
分享igi同学对: 网卡多队列、网卡RPS支持的详细解释和测试数据!
不使用SMP IRQ affinity

使用SMP IRQ affinity

需要大于等于2.4的Linux 内核
示例(把44号中断绑定到前4个CPU(CPU0-3)上面)
示例(把44号中断绑定到前4个CPU(CPU0-3)上面)
这个bitmask表示了76号中断将被路由到哪个指定处理器. bit mask转换成二进制后,其中的每一位代表了一个CPU. smp_affinity文件中的数值以十六进制显示。为了操作该文件,在设置之前我们需要把CPU位掩码从二进制转换到十六进制。
上面例子中每一个”f”代表了4个CPU的集合,最靠右边的值是最低位的意思。 以4个CPU的系统为例:
“f” 是十六进制的值, 二进制是”1111”. 二进制中的每个位代表了服务器上的每个CPU. 那么能用以下方法表示每个CPU
客户端: netperf
服务端: netserver
测试分类: 不开启IRQ affinity和RPS/RFS, 单独开启IRQ affinity, 单独开启RPS/RFS,同时开启IRQ affinity和RPS/RFS, 不同分类设置值如下
不开启IRQ affinity和RPS/RFS
TCP_RR 1 byte: 测试TCP 小数据包 request/response的性能
UDP_RR 1 byte: 测试UDP 小数据包 request/response的性能
TCP_RR 256 byte: 测试TCP 大数据包 request/response的性能
UDP_RR 256 byte: 测试UDP 大数据包 request/response的性能

TCP_RR 256 byte大包测试

UDP_RR 1 byte小包测试

UDP_RR 256 byte大包测试

不开启IRQ affinity和RPS/RFS: 软中断集中在第一个CPU上,导致了性能瓶颈
单独开启IRQ affinity分别提升135%, 343%, 443%
同时开启RPS/RFS和IRQ affinity分别提升148%, 346%, 372%
单独开启IRQ affinity分别提升79%, 77%, 88%
同时开启RPS/RFS和IRQ affinity分别提升79%, 77%, 88%
单独开启IRQ affinity性能分别下降11%, 8%, 8% (这是此次测试的局限造成, 详细分析见: 测试的局限性)
同时开启RPS/RFS和IRQ affinity分别提升65%, 130%, 137%
单独开启IRQ affinity性能分别下降5%, 4%, 4%
同时开启RPS/RFS和IRQ affinity分别提升55%, 51%, 53%
TCP 小数据包应用上,单独开启IRQ affinity能获得最大的性能提升,随着进程数的增加,IRQ affinity的优势越加明显.
UDP 小数据包方面,由于此次测试的局限,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升;
TCP 大数据包应用上,单独开启IRQ affinity性能提升没有小数据包那么显著,但也有接近80%的提升, 基本与单独开启RPS/RFS的性能持平, 根据实验的数据计算所得,此时网卡流量约为88MB,还没达到千兆网卡的极限。
UDP 大数据包应用上,也是同样受测试局限性的影响,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升
Scaling in the Linux Networking Stack
Linux 多核下绑定硬件中断到不同 CPU(IRQ Affinity)
计算 SMP IRQ Affinity
bnx2 RSS hash
Introduction to Receive-Side Scaling
RFS 全称是 Receive Flow Steering, 这也是Tom提交的内核补丁,它是用来配合RPS补丁使用的,是RPS补丁的扩展补丁,它把接收的数据包送达应用所在的CPU上,提高cache的命中率。
这两个补丁往往都是一起设置,来达到最好的优化效果, 主要是针对单队列网卡多CPU环境(多队列多重中断的网卡也可以使用该补丁的功能,但多队列多重中断网卡有更好的选择:SMP IRQ affinity)
应用RPS之前: 所有数据流被分到某个CPU, 多CPU没有被合理利用, 造成瓶颈

应用RPS之后: 同一流的数据包被分到同个CPU核来处理,但可能出现cpu cache迁跃

应用RPS+RFS之后: 同一流的数据包被分到应用所在的CPU核

关于此点改进的详细介绍可以查看LWN上的两篇文章:"Receive packet steering" and "Receive flow steering"。
下面我就自己的理解来做一下阐述,不当之处,多多包涵。
首先是Receive Packet Steering (RPS)
随着单核CPU速度已经达到极限,CPU向多核方向发展,要持续提高网络处理带宽,传统的提升硬件设备、智能处理(如GSO、TSO、UFO)处理办法已不足够。如何充分利用多核势来进行并行处理提高网络处理速度就是RPS解决的课题。
以一个具有8核CPU和一个NIC的,连接在网络中的主机来说,对于由该主机产生并通过NIC发送到网络中的数据,CPU核的并行性是自热而然的事情:

问题主要在于当该主机通过NIC收到从网络发往本机的数据包时,应该将数据包分发给哪个CPU核来处理(有些具有多条接收队列和多重中断线路的NIC可以帮助数据包并行分发,这里考虑普通的NIC,普通的NIC通过RPS来模拟实现并行分发):

普通的NIC来分发这些接收到的数据包到CPU核处理需要一定的知识智能以帮助提升性能,如果数据包被任意的分配给某个CPU核来处理就可能会导致所谓的“cacheline-pingpong”现象:
比如DATA0数据流的第一个包被分发给CPU0来处理,第二个包分发给CPU1处理,第三个包又分发给CPU0处理;而DATA1数据流恰好相反。这样的交替轮换(8核情况交替得更随意)会导致CPU核的CACHE利用过分抖动。

RPS就是消除这种CPU核随意性分配的智能知识,它通过数据包相关的信息(比如IP地址和端口号)来创建CPU核分配的hash表项,当一个数据包从NIC转到内核网络子系统时就从该hash表内获取其对应分配的CPU核(首次会创建表项)。这样做的目的很明显,它将具有相同相关信息(比如IP地址和端口号)的数据包都被分发给同一个CPU核来处理,避免了CPU的CACHE抖动现象,提高处理性能。
有两点细节:
第一,所有CPU核具有等同的被绑定几率,但管理员可以明确设置CPU核的绑定情况;
第二,hash表项的计算是由NIC进行的,不消耗CPU。
RPS的性能优化结果为大致可提升3倍左右。tg3驱动的NIC性能由90,000提升到285,000,而e1000驱动的NIC性能由90,000提升到292,000,其它驱动NIC也得到类似的测试结果。
接下来是Receive flow steering (RFS)
RFS是在RPS上的改进,从上面的介绍可以看到,通过RPS已经可以把同一流的数据包分发给同一个CPU核来处理了,但是有可能出现这样的情况,即给该数据流分发的CPU核和执行处理该数据流的应用程序的CPU核不是同一个:

不仅要把同一流的数据包分发给同一个CPU核来处理,还要分发给其‘被期望’的CPU核来处理就是RFS需要解决的问题。
RFS会创建两个与数据包相关信息(比如IP地址和端口号)的CPU核映射hash表:
1. 一个用于表示期望处理具有该类相关信息数据包的CPU核映射,通过recvmsg()或sendmsg()等系统调用信息来创建该hash表(称之为期望CPU表)。比如运行于CPU0核上的某应用程序调用了recvmsg()从远程机器host1上获取数据,那么NIC对从host1上发过来的数据包的分发期望CPU核就是CPU0。
2. 一个用于表示最近处理过具有该类相关信息数据包的CPU核映射,称这种表为当前CPU表。该表的存在是因为有多线程的情况,比如运行在两个CPU核上的多线程程序(每个核运行一个线程)交替调用recvmsg()系统函数从同一个socket上获取远程机器host1上的数据会导致期望CPU表频繁更改。如果数据包的分发仅由期望CPU表决定则会导致数据包交替分发到这两个CPU核上,很明显,这不是我们想要的效果。
既然CPU核的分配由两个hash表值决定,那么就可以有一个算法来描述这个决定过程:
1. 如果当前CPU表对应表项未设置或者当前CPU表对应表项映射的CPU核处于离线状态,那么使用期望CPU表对应表项映射的CPU核。
2. 如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核为同一个,那么好办,就使用这一个核。
3. 如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核不为同一个,那么:
a) 如果同一流的前一段数据包未处理完,那么必须使用当前CPU表对应表项映射的CPU核,以避免乱序。
b) 如果同一流的前一段数据包已经处理完,那么则可以使用期望CPU表对应表项映射的CPU核。
算法的前两步比较好理解,而对于第三步可以用下面两个图来帮助理解。应用程序APP0有两个线程THD0和THD1分别运行在CPU0核和CPU1核上,同时CPU1核上还运行有应用程序APP1。首先THD1调用recvmsg()获取远程数据(数据流称之为FLOW0),此时FLOW0的期望CPU核为CPU1,随着数据块FLOW0 : 0的到来并交给CPU1核处理,此时FLOW0的当前CPU核也为CPU1。如果此时THD0也在同一个socket上调用recvmsg()获取远程数据(数据流同样也是FLOW0),那么FLOW0的期望CPU核就改变为CPU0(当前CPU核仍然为CPU1)。与此同时,NIC收到数据块FLOW0 : 1,如何将该数据块分发给CPU核就到了上面算法的第三步。
分情况判断:
1. 如果同一流的前一段数据包FLOW0 : 0未处理完,那么必须使用当前CPU核CPU1来处理新到达的数据块,以避免乱序。如下图所示(FLOW1流是应用程序APP1的):

2. 如果同一流的前一段数据包FLOW0 : 0已经处理完毕,那么可以使用期望CPU核CPU0来处理新到达的数据块。如下图所示(FLOW1流是应用程序APP1的):

RFS适用于面向流的网络协议,它能更好的提升CPU的CACHE效率,不论是内核还是应用程序本身。RFS的性能优化结果在普通环境下为大致可提升3倍左右,而在多线程环境大致可提升2倍。能通过软件的形式提升机器网络带宽性能自然也是再好不过的事情了。
可以参考人人网运维兄弟的文章:
/article/4256365.html
2014-06-18
今天观察了一下web服务器,发现如下问题,当没有绑定软中断的时候,us的cpu都是压在偶数核上面
软中断配置如下:
for i in ` cat /proc/interrupts|grep eth|awk -F":" '{print $1}'`; do cat /proc/irq/$i/smp_affinity; done
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
以下是top看到情况:
Cpu0 : 60.5%us, 6.6%sy, 0.0%ni, 17.6%id, 0.0%wa, 1.0%hi, 14.3%si, 0.0%st
Cpu1 : 2.0%us, 1.0%sy, 0.0%ni, 97.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 22.9%us, 4.3%sy, 0.0%ni, 72.4%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu3 : 4.0%us, 1.0%sy, 0.0%ni, 95.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu4 : 26.9%us, 4.3%sy, 0.0%ni, 68.1%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu5 : 1.0%us, 0.7%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu6 : 26.2%us, 4.0%sy, 0.0%ni, 69.4%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu7 : 2.0%us, 0.7%sy, 0.0%ni, 96.3%id, 0.7%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu8 : 39.2%us, 5.3%sy, 0.0%ni, 54.5%id, 0.0%wa, 0.0%hi, 1.0%si, 0.0%st
Cpu9 : 2.7%us, 2.0%sy, 0.0%ni, 95.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu10 : 29.9%us, 6.0%sy, 0.0%ni, 63.5%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu11 : 1.3%us, 2.0%sy, 0.0%ni, 96.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu12 : 26.0%us, 5.0%sy, 0.0%ni, 68.3%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu13 : 2.0%us, 1.7%sy, 0.0%ni, 96.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu14 : 27.9%us, 4.0%sy, 0.0%ni, 67.4%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu15 : 2.7%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 97.3%si, 0.0%st
当绑定软中断之后,都是压在固定的几个cpu核上,奇怪了。
在前阵子看到HelloDB的一篇文章“MySQL单机多实例方案”中提到:
因为单机运行多个实例,必须对网络进行优化,我们通过多个的IP的方式,将多个MySQL实例绑定在不同的网卡上,从而提高整体的网络能力。还有一种更高级的做法是,将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率。
于是,对“将不同网卡的中断与CPU绑定,这样可以大幅度提升网卡的效率”比较感兴趣,所以找了点资料了解一下。先总结如下:
1. 不同的设备一般都有自己的IRQ号码(当然一个设备还有可能有多个IRQ号码)
通过命令:cat /proc/interrupts查看
如:cat /proc/interrupts | grep -e “CPU\|eth4″
#当使用KVM中的device assignment特性时,在/proc/interrupts中,有“ … IR-PCI-MSI-edge kvm:0000:05:00.1 …”这样的行。
2. 中断的smp affinity在cat /proc/irq/$Num/smp_affinity
可以echo “$bitmask” > /proc/irq/$num/smp_affinity来改变它的值。
如: echo 8 > /proc/irq/93/smp_affinity #表示将93号irq绑定到#3号CPU
echo 400 > /proc/irq/93/smp_affinity #表示将93号irq绑定到#10号CPU(我们可以用工具将16进制400转换为二进制为10000000000)
注意smp_affinity这个值是一个十六进制的bitmask,它和cpu No.序列的“与”运算结果就是将affinity设置在那个(那些)CPU了。(也即smp_affinity中被设置为1的位为CPU No.)
比如:我有8个逻辑core,那么CPU#的序列为11111111 (从右到左依次为#0~#7的CPU)
如果cat /proc/irq/84/smp_affinity的值为:20(二进制为:00100000),则84这个IRQ的亲和性为#5号CPU。
每个IRQ的默认的smp affinity在这里:cat /proc/irq/default_smp_affinity
另外,cat /proc/irq/$Num/smp_affinity_list 得到的即是irq绑定的CPU的一个List。
3. 默认情况下,有一个irqbalance在对IRQ进行负载均衡,它是/etc/init.d/irqbalance
在某些特殊场景下,可以根据需要停止这个daemon进程。
4. 如果要想提高性能,将IRQ绑定到某个CPU,那么最好在系统启动时,将那个CPU隔离起来,不被scheduler通常的调度。
可以通过在Linux kernel中加入启动参数:isolcpus=cpu-list来将一些CPU隔离起来。
参考:http://smilejay.com/2012/02/irq_affinity/
http://blog.yufeng.info/archives/2037 *****MYSQL数据库网卡软中断不平衡问题及解决方案
LVS网卡软中断配置这是之前做LVS的网卡软中断配置时整理的一个文档,网上的资料不是很全,将配置方法share给大家。
为什么要配置网卡软中断,主要是因为在网络非常 heavy 的情况下,对于文件服务器、高流量 Web 服务器这样的应用来说,把不同的网卡 IRQ 均衡绑定到不同的 CPU 上将会减轻某个 CPU 的负担,提高多个 CPU 整体处理中断的能力。合理的根据自己的生产环境和应用的特点来平衡 IRQ 中断有助于提高系统的整体吞吐能力和性能。
先看下未升级之前的效果:可以看到网卡软中断被分配到了两个指定的CPU核心上(看%si列):
经过升级内核调整参数后的效果:
软中断被均匀的分配到8个核心上,下面来说下具体过程
首先,将内核升级到2.6.32以上,升级过程略去:
为什么要将2.6.18内核升级到2.6.32?
这个主要是因为2.6.18还丌支持RPS这个特性
那什么是rps呢?具体可以参看: http://lwn.net/Articles/328339/ http://lwn.net/Articles/378617/
为什么要将2.6.18内核升级到2.6.32?
这个主要是因为2.6.18不支持RPS这个特性
那什么是rps呢?具体可以参看: http://lwn.net/Articles/328339/ http://lwn.net/Articles/378617/
第二步:
如果你的服务器网卡和我一样是Broadcom的,那么你就得做这一步,不是请跳到第三步(待deven确认)
在/etc/modprobe.conf加上下面这行: options bnx2 disable_msi=1
改完这个重新加载下网卡模块modprobe -r bnx2;modprobe bnx2或者重新启动服务器。
redhat 6.1或以上版本系统,没有“/etc/modprobe.conf”这个文件,需要编辑“/etc/modprobe.d/dist.conf”。重新加载网卡后可以用“modprobe -c|grep bnx2”查看配置有没有生效
为什么要加这个?
这个主要是因为broadcom网卡开启msi后,会造成后面的修改smp_affinity丌生效,intel的网卡没这个问题。
msi是什么?下面的链接有解析: http://lwn.net/Articles/44139/ 第三步:
停用irqbalance
/etc/init.d/irqbalance stop
这个是一个自动调整中断的工具,有兴趣的可以看下irqbalance的官方网站: http://irqbalance.org/ 第四步:
设置eth0、eth1对应中断号的 smp_affinity 为 “ff”
先看一下网卡的中断号:
从图中可以看到网卡eth1的中断号为16,eth0的中断号为18
将/proc/irq/中断号/smp_affinity修改为ff,修改完成后就可以开启lvs了,现在中断应该均分到各个核心上了。
smp_affinity这个参数是怎么得来的? 可参考下面链接:
http://www.cs.uwaterloo.ca/~brecht/servers/apic/SMP-affinity.txt
这个也可以看看: http://www.cnblogs.com/Bozh/archive/2013/01/17/2864201.html
http://www.docin.com/p-289489132.html (盛大的)
以下这篇文章转自:http://hi.baidu.com/excalibur/item/77122ebeb0544242bb0e1236
Linux Virtual Server (LVS)之:ksoftirqd进程耗尽单核100%si处理软中断导致性能瓶颈
最近测试LVS性能,发现当CPU其中一个核耗尽后系统达到性能顶峰。消耗CPU资源的是ksoftirqd进程,全部用于处理软中断(从进程名也能识别出了)。
搜了一下,很多人都遇到这类问题,似乎也没有解决。了解到并尝试过的解决方案有:
1、减少集群成员的数量;
2、修改集群模式(NAT、TURNL、DR);
3、修改集群调度算法;
4、升级操作系统内核到2.6.20以上;
5、调整网卡的最大传输单元(MTU);
6、修改设备中断方式;
7、使用多网卡负载均衡;
8、升级硬件(网卡);
9、更换操作系统。
一一解说如下吧:
第1点:减少集群成员的数量。由于瓶颈不在真实服务器上,所以减少成员数量,lvs性能没有明显变化。
第2点:修改集群模式。理论上DR模式是最省资源的,大概了解理论的朋友应该都知道。由于NAT模式不满足需求,故仅对比了DR和TUN模式,两者没有明显区别。
第3点:修改集群调度算法。已有的十种算法中属rr最简单,而且目前瓶颈还未深入到这一层。实际上在处理网络包的时候导致的瓶颈。调度算法简单比较了rr和wrr,两者没有明显区别。
第4点:升级操作系统内核到2.6.20以上。我直接升级到当前已发布的最新版本2.6.34,结果瓶颈并没有得到改善。
第5点:调整网卡的最大传输单元。交换机支持最大的传输单元是9216,将网卡的最大传输单元分别修改为:1500(默认)、5000、9000、9216。其中1500和5000两者没有明显差别,9000和9216会导致网络不稳定,性能也没有提高反而出现大量连接超时。
第6点:修改设备中断方式。通过修改设置中断/proc/irq/${网卡中断号}/smp_affinity:
测试服务器CPU为四核,理论上网卡的smp_affinity值为1、2、4、8分别对应cpu0、cpu1、cpu2、cpu3。
结果:
1、网卡的smp_affinity默认值为8,测试过程中软中断全部由cpu3处理。正确
2、设置smp_affinity = 1,测试过程中软中断全部由cpu0处理。正确
3、设置smp_affinity = 2,测试过程中软中断全部由cpu1处理。正确
4、设置smp_affinity = 4,测试过程中软中断全部由cpu2处理。正确
5、设置smp_affinity = 5,测试过程中软中断全部由cpu0处理,预期应该分配给cpu0和cpu2处理。无效
6、设置smp_affinity = f,测试过程中软中断全部由cpu0处理,预期应该分配给cpu0、cpu1、cpu2和cpu2处理。无效(经过Deven验证,的确如此)
即:修改smp_affinity的功能只针对单核有效。(Deven:按照我的理解,应该是说设置smp_affinity只能绑定到一个cpu核,绑定多核是不生效的,如果作者把有多个网卡中断号的网卡绑定到不同cpu应该是可行,他说不可行,应该是他的网卡为非多队列)
第7点:使用多网卡负载均衡。此方案可行!使用两张网卡绑定一个IP地址,性能就提升了一倍,效果非常明显。原因就是两张网卡各用一个CPU核,相比用单核而言,性能自然提升一倍。
配置方式如下:
单网卡工作模式
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
BOOTPROTO=none
BROADCAST=192.168.223.255
HWADDR=00:1E:90:76:6F:E0
IPADDR=192.168.223.113
NETMASK=255.255.254.0
NETWORK=10.20.222.0
ONBOOT=yes
GATEWAY=192.168.222.1
TYPE=Ethernet
绑定双网卡操作步骤
echo 'alias bond0 bonding' >> /etc/modprobe.conf
# cat /etc/sysconfig/network-scripts/ifcfg-bond0
DEVICE=bond0
BOOTPROTO=static
BROADCAST=192.168.223.255
MACDDR=00:1E:90:76:6F:E2
IPADDR=192.168.223.113
NETMASK=255.255.254.0
NETWORK=192.168.222.0
USERCTL=no
ONBOOT=yes
GATEWAY=10.20.222.1
TYPE=Ethernet
BONDING_OPTS="mode=0 miimon=100"
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ERCTL=no
ONBOOT=yes
MASTER=bond0
SLAVE=yes
BOOTPROTO=none
# cat /etc/sysconfig/network-scripts/ifcfg-eth1
DEVICE=eth1
USERCTL=no
ONBOOT=yes
MASTER=bond0
SLAVE=yes
BOOTPROTO=none
# service network restart
[b]第8点,升级硬件,使用支持RSS功能的网卡。 [/b]
下面是intel对RSS的说明
Receive-side scaling (RSS) routes incoming packets to specific queues, efficiently balancing network loads across CPU cores and increasing performance on multi-processor systems. RSS, called Scalable I/O in Linux*, creates a hash table from IP, TCP, and Port Addresses and uses that table to decide which queue to route a packet to, and to which processor the packet should be associated.
可是从我们使用网卡的官网硬件指标上,都是支持RSS的。Windows的设置方式是`[b]netsh int tcp set global rss=enabled`。 [/b]
第9点,更换操作系统。此方案在生产环境下部署的可能性比较小,但是否关操作系统的事确实需要确认。
据说Windows的NLB、solaris、AIX支持网卡RSS,目前还有待确认。
大量小包的CPU密集型系统调优案例一则
http://blog.netzhou.net/?p=181我的blog前面有一篇文章描述了软终端导致单cpu消耗100%,导致机器丢包跟延迟高的问题,文中我只是简单的说明了一下升级内核进行解决的,这个问题我并没有进行一个问题解决的说明,经历了一系列的调整后,单机的并发从单机单网卡承受100M流量到160M流量,到现在的最高的230M流量,在程序没有大规模修改的情况下效果还是十分的明显,这次这篇文章将完整的说一下我的一个解决方法:
先说说我的场景,我目前负责的一个项目,大量的小数据包,长连接,每个数据包都不大,大概10Kbit左右一个包,但是数量十分之大,目前在生产环境中最大的数据包数量高达15W/s的数量,常见的网游系统,小图片cdn系统,这些服务类型都算是这种类型,单网卡流量不大,但是数据包数量极大,我目前调优的结果是
在Xeon E5504, BCM5716的网卡,8G的dell r410的机器,单网卡实现了230MBits大的流量,系统的load为0,8颗cpu每一颗还有10%左右的IDLE,由于我们的系统是数据包的转发,还有一个网卡同期的流量使220M,12.8W的数据包,算上总数,大概可以到450MBits的流量,25.5W的小包,由于人数有限,流量没有跑上去,预计可以跑到480MBits的流量,生产环境的一台机器的数据:
流量及机器的网卡包数量
机器的cpu消耗
首先机器的选型,由于大量小包的cpu密集的系统,当然cpu越性能越高越好咯,但是成本相应的高。对于这种类型的机器,网卡选型也是十分的重要,一定要选择支持msi-x的网卡类型,什么是msi-x大家可以查询google资料去了解一下,目前市面出售的大部分最新的网卡都有这个功能,查看方法lspci -v,看到如下图的内容
再者网卡是否支持多队列,多队列网卡十分的重要,不是多队列的网卡,这篇文章几乎不需要看了,可以直接忽略掉,查看方法cat /proc/interrupts,这个方法并不适用所有的操作系统例如在rhel 5.5的os当中,bcm5716的网卡就看不到,具体我也没有查到怎么查看的方法,麻烦知道的用户告知一声,如果是的话应该可以看到如下图的内容
每一个网卡有8个队列,对于这种大量小包的cpu密集型的系统,多队列的网卡性能至少***能50%以上,我们生产环境的有台非多队列的Intel 82574的网卡调优后只能跑到160M左右流量,跟上图明显的一个对比.而同等情况下买一个多队列的网卡明显要便宜很多。
操作系统的选择,目前大部分企业使用的是rhel系列的os,包括标准的rhel跟centos作为一个生产环境的os,目前主力的版本还是rhel 5系列的os,而rhel 5系列的内核版本对于软中断处理并不是很好,调优的结果不是很理想,在rhel 5系列的os上,我们最高流量单网卡也就是160M左右,而且机器的load也很高了,机器已经出现小量的丢包,而且只是使用了4到6个cpu还有几个cpu没有利用上,机器性能没有挖掘完毕,由于我们的机器没有存储的压力,单纯的只是消耗cpu资源,没有io的压力,于是大胆的启用刚出的rhel 6.1的系统,看重这个系统的原因是,该os的内核已经加入了google的两个原本在2.6.35当中才启用的2个补丁――RPS/RFS,RPS主要是把软中断的负载均衡到各个cpu,由于RPS只是单纯把数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对于cpu cache的影响会很大,那么RFS确保应用程序处理的cpu跟软中断处理的cpu是同一个,这样就充分利用cpu的cache,默认情况下,这个功能并没有开启,需要手动开启开启方法,开启的前提是多队列网卡才有效果。
echo ff > /sys/class/net/<interface>/queues/rx-<number>/rps_cpus
echo 4096 > /sys/class/net/<interface>/queues/rx-<number>/rps_flow_cnt
echo 30976 > /proc/sys/net/core/rps_sock_flow_entries(经过Deven在虚拟机测试,centos6.4版本,设置上面3个选项就搞定了)
对于2个物理cpu,8核的机器为ff,具体计算方法是第一颗cpu是00000001,第二个cpu是00000010,第3个cpu是00000100,依次类推,由于是所有的cpu都负担,所以所有的cpu数值相加,得到的数值为11111111,十六进制就刚好是ff。而对于/proc/sys/net/core/rps_sock_flow_entries的数值是根据你的网卡多少个通道,计算得出的数据,例如你是8通道的网卡,那么1个网卡,每个通道设置4096的数值,8*4096就是/proc/sys/net/core/rps_sock_flow_entries的数值,对于内存大的机器可以适当调大rps_flow_cnt,这个时候基本可以把软中断均衡到各个cpu上了,而对于cpu的使用,还有其它的例如use,sys等,这个不均衡的话,cpu还是会浪费掉,同时对我们的程序针对多cpu进行小部分的开发跟重新编译,本身我们程序就是多进程的一个模型,我们采用nginx的进程管理模型,一个master管理work进程,master分配每一个连接给work进程,由work进程处理用户的请求,这样每一个进程都能均衡负担几乎相同的处理请求,同时在6.1的系统中gcc新增一个openmp的指令,这个指令作用针对多核,增加程序的并行计算的功能,不需要大规模的更改代码就能实现多核的并行性计算,具体使用使用方法请见如下urlhttp://zh.wikipedia.org/zh/OpenMP针对上面的处理,基本上可以实现cpu按理说可以实现完全的均衡了,但是当我们在实际的使用过程中发现还是cpu还不是100%的均衡,存在1到2个cpu消耗量还是比其它的要大20%左右,导致在高峰期有1到2个cpu的idle使用完毕,导致用户使用存在卡的情况,这个时候,需要手动调节一下cpu的使用情况,在这操作之前先了解几个名词以及其作用
一个是IO-APIC(输入输出装置的高级可编程中断控制器)
为了充分挖掘 SMP 体系结构的并行性,能够把中断传递给系统中的每个CPU至关重要,基于此理由,Intel 引入了一种名为 I/O-APIC的东西。该组件包含两大组成部分:一是“本地 APIC”,主要负责传递中断信号到指定的处理器;举例来说,一台具有三个处理器的机器,则它必须相对的要有三个本地 APIC。另外一个重要的部分是 I/O APIC,主要是收集来自 I/O 装置的 Interrupt 信号且在当那些装置需要中断时发送信号到本地 APIC。这样就能充分利用多cpu的并行性。如果用户对于IO-APIC更感兴趣,请见如下url的中的pdf的说明http://wenku.baidu.com/view/ccdc114e2e3f5727a5e962e9.html另外一个就是irqbalance
irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode.处于 Performance mode时irqbalance 会将中断尽可能均匀地分发给各个CPU以充分利用 CPU 多核,提升性能.处于 Power-save mode时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗
通过这我们就发现我们是一个非常繁重的系统,并没有节能的需求,而是需要充分利用各个cpu的性能,而事实上在一个大量小包的系统上,irqbalance优化几乎没有效果,而且还使得cpu消耗不均衡,导致机器性能得不到充分的利用,这个时候需要把它给结束掉
/etc/init.d/irqbalance stophttp://blog.yufeng.info/archives/2422 ****深度剖析告诉你irqbalance有用吗?同时,手动绑定软中断到指定的cpu,对于一个8个队列的网卡,8核的机器,可以指定一个cpu处理一个网卡队列的中断请求,并根据cpu的消耗情况,手动调整单个网卡的队列到资源消耗低的cpu上,实现手动均衡,具体操作方法,执行如下命令
cat /proc/interrupts
计算cpu的方法第一颗为00000001换算成16进制为1,第2颗cpu为00000010换算成16进制为2,依次类推得出,第8颗cpu为80,这样就可以做如下的绑定了
echo 0001 > /proc/irq/<number>/smp_affinity
这样就可以绑定中断到指定的cpu了,这个时候有可能会问,我的机器是一个2通道的网卡,这个时候如果一个通道一个cpu绑定,这个时候就浪费了6颗cpu了,还是达不到完全均衡负载,为什么不能像前面rps那样,
echo ff > /proc/irq/<number>/smp_affinity
设置一个ff达到所有的cpu一起均衡呢,这个因为io-apic工作的2个模式logical/low priority跟fixed/physical模式,这两个模式的区别在于,前面一个模式能够把网卡中断传递给多核cpu进行处理,后一种模式对应一个网卡队列的中断只能传递给单cpu进行处理,而linux是fixed/physical工作模式,如果你设置上面那个选项,只能第一个cpu进行软中断的处理,又回到未优化前了。那么为什么不开启logical/low priority呢,当一个tcp连接发起,当数据包到底网卡,网卡触发中断,中断请求到其中一个cpu,而logical/lowpriority并不能保证后续的数据包跟前面的包处于同一个cpu,这样后面的数据包发过来,又可能处于另外一个cpu,这个时候同一个socket都得检查自己的cpu的cache,这样就有可能部分cpu取不到数据,因为本身它的cache并没用数据,这个时候就多了多次的cpu的查找,不能充分利用cpu的效率。对于部分机器来说并不能开启logical/low priority模式,一种可能是cpu过多,另外一种是bios不支持。因此对于那种单队列网卡并不能充分发挥cpu的性能。
经过上述的调整基本可以达到几乎完全均衡的效果,每个cpu都能发挥他的效果。也几乎可以到达我调优的效果
对于一个完整的系统来说,不仅有数据包发送的需求还有数据接收的请求,而rps/rfs主要解决数据接收的一个中断均衡的问题,rps/rfs的作者提交了一个xps(Transmit Packet Steering), 这个patch主要是针对多队列的网卡发送时的优化,当发送一个数据包的时候,它会根据cpu来选择对应的队列,目前这个patch已经添加在2.6.38内核版本当中,我们已经在生产环境中,部分机器上已经使用上了,据作者的benchmark,能够提高20%的性能,具体使用方法
echo ff > /sys/class/net/<interface>/queues/tx-<number>/xps_cpus
由于还是新上的系统,还没敢大规模放用户进来,还在测试系统的稳定性,不知道上限具体能到多少,从当前生产环境跑的流量来看,比同等其它的机器,cpu消耗情况,确实要减少一些,流量没有跑上来,效果不是特别的明显,还有待继续测试,得出一个具体的结果。
另外对于intel的网卡的用户,intel有个叫ioat的功能,关于ioat功能大家可以网上查查资料.
而对于centos的用户来说,目前还只是出了6.0的版本,并没有上述功能,要大规模的推广,建议大家编译2.6.38的内核版本,因为2.6.38的版本已经包含了上述几个补丁。编译内核生成内核的rpm包,能快速的在同一批机器上快速部署上去。
以上就是我的对cpu密集型系统的一个优化过程,欢迎大家来讨论。
关于Linux网卡调优之:RPS (Receive Packet Steering)
参考:http://hi.baidu.com/higkoo/item/9f2b50d9adb177cd1a72b4a8(淘宝的)昨天在查LVS调度均衡性问题时,最终确定是 persistence_timeout 参数会使用IP哈希。目的是为了保证长连接,即一定时间内访问到的是同一台机器。而我们内部系统,由于出口IP相对单一,所以总会被哈希到相同的RealServer。
随后和 @吴佳明_普空八卦LVS压力大的问题,他推荐我使用RPS。小搜一下,瞬间发现这真是个宝贝!
过去使用LVS,遇到过单核CPU被软中断耗尽的问题,然后知道了网卡驱动与多队列。而后知道了淘宝对LVS的优化,然后对生产环境进行了优化,效果显著。
如今单台LVS带宽吃到近500Mb/s,每秒进出包都过40万。此时发现网卡(4队列)对应CPU的软中断消耗已过40%了,倍感压力。按理,空闲CPU如果少于40%,则要新增节点了。关于中断不均衡的问题,听取了普空的意见,效果也非常明显,全均衡了:
原来CentOS 6.1就开始支持RPS了,原生支持需要使用Linux内核2.6.38或以上版本。
简单来讲,RPS就是让网卡使用多核CPU的。传统方法就是网卡多队列(RSS,需要硬件和驱动支持),RPS则是在系统层实现了分发和均衡。献上修改设置的脚本一例:
http://bbs.chinaunix.net/forum.php?mod=viewthread&action=printable&tid=1927269
多队列网卡简介
http://blog.csdn.net/turkeyzhou/article/details/7528182
多队列网卡是一种技术,最初是用来解决网络IO QoS (quality of service)问题的,后来随着网络IO的带宽的不断提升,单核CPU不能完全处满足网卡的需求,通过多队列网卡驱动的支持,将各个队列通过中断绑定到不同的核上,以满足网卡的需求。常见的有Intel的82575、82576,Boardcom的57711等,下面以公司的服务器使用较多的Intel 82575网卡为例,分析一下多队列网卡的硬件的实现以及linux内核软件的支持。
1.多队列网卡硬件实现
图1.1是Intel 82575硬件逻辑图,有四个硬件队列。当收到报文时,通过hash包头的SIP、Sport、DIP、Dport四元组,将一条流总是收到相同的队列。同时触发与该队列绑定的中断。图1.1 82575硬件逻辑图
2. 2.6.21以前网卡驱动实现
kernel从2.6.21之前不支持多队列特性,一个网卡只能申请一个中断号,因此同一个时刻只有一个核在处理网卡收到的包。如图2.1,协议栈通过NAPI轮询收取各个硬件queue中的报文到图2.2的net_device数据结构中,通过QDisc队列将报文发送到网卡。图2.1 2.6.21之前内核协议栈
图2.2 2.6.21之前net_device
3. 2.6.21后网卡驱动实现
2.6.21开始支持多队列特性,当网卡驱动加载时,通过获取的网卡型号,得到网卡的硬件queue的数量,并结合CPU核的数量,最终通过Sum=Min(网卡queue,CPU core)得出所要激活的网卡queue数量(Sum),并申请Sum个中断号,分配给激活的各个queue。如图3.1,当某个queue收到报文时,触发相应的中断,收到中断的核,将该任务加入到协议栈负责收包的该核的NET_RX_SOFTIRQ队列中(NET_RX_SOFTIRQ在每个核上都有一个实例),在NET_RX_SOFTIRQ中,调用NAPI的收包接口,将报文收到CPU中如图3.2的有多个netdev_queue的net_device数据结构中。这样,CPU的各个核可以并发的收包,就不会应为一个核不能满足需求,导致网络IO性能下降。图3.1 2.6.21之后内核协议栈
图3.2 2.6.21之后net_device
4.中断绑定
当CPU可以平行收包时,就会出现不同的核收取了同一个queue的报文,这就会产生报文乱序的问题,解决方法是将一个queue的中断绑定到唯一的一个核上去,从而避免了乱序问题。同时如果网络流量大的时候,可以将软中断均匀的分散到各个核上,避免CPU成为瓶颈。图4.1 /proc/interrupts
5.中断亲合纠正
一些多队列网卡驱动实现的不是太好,在初始化后会出现图4.1中同一个队列的tx、rx中断绑定到不同核上的问题,这样数据在core0与core1之间流动,导致核间数据交互加大,cache命中率降低,降低了效率。图5.1 不合理中断绑定linux network子系统的负责人David Miller提供了一个脚本,首先检索/proc/interrupts文件中的信息,按照图4.1中eth0-rx-0($VEC)中的VEC得出中断MASK,并将MASK写入中断号53对应的smp_affinity中。由于eth-rx-0与eth-tx-0的VEC相同,实现同一个queue的tx与rx中断绑定到一个核上,如图4.3所示。
图4.2 set_irq_affinity
图4.3 合理的中断绑定
set_irq_affinity脚本位于http://mirror.oa.com/tlinux/tools/set_irq_affinity.sh。
6.多队列网卡识别
#lspci -vvvEthernet controller的条目内容,如果有MSI-X && Enable+ && TabSize > 1,则该网卡是多队列网卡,如图4.4所示。图4.4 lspci内容Message Signaled Interrupts(MSI)是PCI规范的一个实现,可以突破CPU 256条interrupt的限制,使每个设备具有多个中断线变成可能,多队列网卡驱动给每个queue申请了MSI。MSI-X是MSI数组,Enable+指使能,TabSize是数组大小。
关于Linux网卡调优之:RPS (Receive Packet Steering)
昨天在查LVS调度均衡性问题时,最终确定是 persistence_timeout 参数会使用IP哈希。目的是为了保证长连接,即一定时间内访问到的是同一台机器。而我们内部系统,由于出口IP相对单一,所以总会被哈希到相同的RealServer。随后和 @吴佳明_普空八卦LVS压力大的问题,他推荐我使用RPS。小搜一下,瞬间发现这真是个宝贝!
过去使用LVS,遇到过单核CPU被软中断耗尽的问题,然后知道了网卡驱动与多队列。而后知道了淘宝对LVS的优化,然后对生产环境进行了优化,效果显著。
如今单台LVS带宽吃到近500Mb/s,每秒进出包都过40万。此时发现网卡(4队列)对应CPU的软中断消耗已过40%了,倍感压力。按理,空闲CPU如果少于40%,则要新增节点了。关于中断不均衡的问题,听取了普空的意见,效果也非常明显,全均衡了:
原来CentOS 6.1就开始支持RPS了,原生支持需要使用Linux内核2.6.38或以上版本。
简单来讲,RPS就是让网卡使用多核CPU的。传统方法就是网卡多队列(RSS,需要硬件和驱动支持),RPS则是在系统层实现了分发和均衡。献上修改设置的脚本一例:
SMP IRQ affinity
Linux 2.4内核之后引入了将特定中断绑定到指定的CPU的技术,称为SMP IRQ affinity.原理
当一个硬件(如磁盘控制器或者以太网卡), 需要打断CPU的工作时, 它就触发一个中断. 该中断通知CPU发生了某些事情并且CPU应该放下当前的工作去处理这个事情. 为了防止多个设置发送相同的中断, Linux设计了一套中断请求系统, 使得计算机系统中的每个设备被分配了各自的中断号, 以确保它的中断请求的唯一性. 从2.4 内核开始, Linux改进了分配特定中断到指定的处理器(或处理器组)的功能. 这被称为SMP IRQ affinity, 它可以控制系统如何响应各种硬件事件. 允许你限制或者重新分配服务器的工作负载, 从而让服务器更有效的工作. 以网卡中断为例,在没有设置SMP IRQ affinity时, 所有网卡中断都关联到CPU0, 这导致了CPU0负载过高,而无法有效快速的处理网络数据包,导致了瓶颈。 通过SMP IRQ affinity, 把网卡多个中断分配到多个CPU上,可以分散CPU压力,提高数据处理速度。不使用SMP IRQ affinity
使用SMP IRQ affinity
使用前提
需要多CPU的系统需要大于等于2.4的Linux 内核
相关设置文件
1. /proc/irq/IRQ#/smp_affinity
/proc/irq/IRQ#/smp_affinity 和 /proc/irq/IRQ#/smp_affinity_list 指定了哪些CPU能够关联到一个给定的IRQ源. 这两个文件包含了这些指定cpu的cpu位掩码(smp_affinity)和cpu列表(smp_affinity_list). 不允许关闭所有CPU, 同时如果IRQ控制器不支持中断请求亲和(IRQ affinity),则这些设置的值将保持不变(既关联到所有CPU). 设置方法如下2. /proc/irq/IRQ#/smp_affinity_list
设置该文件取得的效果与/proc/irq/IRQ#/smp_affinity是一致的,它们两者是联动关系(既设置其中之一,另一个文件也随着改变), 有些系统可能没有该文件, 设置方法如下3. /proc/irq/default_smp_affinity
/proc/irq/default_smp_affinity 指定了默认情况下未激活的IRQ的中断亲和掩码(affinity mask).一旦IRQ被激活,它将被设置为默认的设置(即default_smp_affinity中记录的设置). 该文件能被修改. 默认设置是0xffffffff.bitmask计算方法
首先我们来看看smp_affinity文件的内容上面例子中每一个”f”代表了4个CPU的集合,最靠右边的值是最低位的意思。 以4个CPU的系统为例:
“f” 是十六进制的值, 二进制是”1111”. 二进制中的每个位代表了服务器上的每个CPU. 那么能用以下方法表示每个CPU
二进制 十六进制 CPU 0 0001 1 CPU 1 0010 2 CPU 2 0100 4 CPU 3 1000 8结合这些位掩码(简单来说就是直接对十六进制值做加法), 我们就能一次定位多个CPU。 例如, 我想同时表示CPU0和CPU2, bitmask结果就是(我们是需要把
转换为16进制之后再写入smp_affinity):
二进制 十六进制 CPU 0 0001 1 + CPU 2 0100 4 ----------------------- bitmask 0101 5如果我想一次性表示所有4个CPU,bitmask结果是:
二进制 十六进制 CPU 0 0001 1 CPU 1 0010 2 CPU 2 0100 4 + CPU 3 1000 8 ----------------------- bitmask 1111 f假如有一个4个CPU的系统, 我们能给一个IRQ分配15种不同的CPU组合(实际上有16种,但我们不能给任何中断分配中断亲和为”0”的值, 即使你这么做,系统也会忽略你的做法)
对比测试
| 类别 | 测试客户端 | 测试服务端 |
|---|---|---|
| 型号 | BladeCenter HS22 | BladeCenter HS22 |
| CPU | Xeon E5640 | Xeon E5640 |
| 网卡 | Broadcom NetXtreme II BCM5709S Gigabit Ethernet | Broadcom NetXtreme II BCM5709S Gigabit Ethernet |
| 内核 | 2.6.38-2-686-bigmem | 2.6.38-2-686-bigmem |
| 内存 | 24GB | 24GB |
| 系统 | Debian 6.0.3 | Debian 6.0.3 |
| 驱动 | bnx2 | bnx2 |
服务端: netserver
测试分类: 不开启IRQ affinity和RPS/RFS, 单独开启IRQ affinity, 单独开启RPS/RFS,同时开启IRQ affinity和RPS/RFS, 不同分类设置值如下
不开启IRQ affinity和RPS/RFS
/proc/irq/74/smp_affinity 00ffff /proc/irq/75/smp_affinity 00ffff /proc/irq/76/smp_affinity 00ffff /proc/irq/77/smp_affinity 00ffff /proc/irq/78/smp_affinity 00ffff /proc/irq/79/smp_affinity 00ffff /proc/irq/80/smp_affinity 00ffff /proc/irq/81/smp_affinity 00ffff /sys/class/net/eth0/queues/rx-0/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-1/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-2/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-3/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-4/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-5/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-6/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-7/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 0 /proc/sys/net/core/rps_sock_flow_entries 0单独开启IRQ affinity(Deven:奇怪了,我们服务器没有看到
/sys/class/net/eth0/queues目录)
/proc/irq/74/smp_affinity 000001 /proc/irq/75/smp_affinity 000002 /proc/irq/76/smp_affinity 000004 /proc/irq/77/smp_affinity 000008 /proc/irq/78/smp_affinity 000010 /proc/irq/79/smp_affinity 000020 /proc/irq/80/smp_affinity 000040 /proc/irq/81/smp_affinity 000080 /sys/class/net/eth0/queues/rx-0/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-1/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-2/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-3/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-4/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-5/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-6/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-7/rps_cpus 00000000 /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 0 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 0 /proc/sys/net/core/rps_sock_flow_entries 0单独开启RPS/RFS
/proc/irq/74/smp_affinity 00ffff /proc/irq/75/smp_affinity 00ffff /proc/irq/76/smp_affinity 00ffff /proc/irq/77/smp_affinity 00ffff /proc/irq/78/smp_affinity 00ffff /proc/irq/79/smp_affinity 00ffff /proc/irq/80/smp_affinity 00ffff /proc/irq/81/smp_affinity 00ffff /sys/class/net/eth0/queues/rx-0/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-1/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-2/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-3/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-4/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-5/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-6/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-7/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096 /proc/sys/net/core/rps_sock_flow_entries 32768同时开启IRQ affinity和RPS/RFS
/proc/irq/74/smp_affinity 000001 /proc/irq/75/smp_affinity 000002 /proc/irq/76/smp_affinity 000004 /proc/irq/77/smp_affinity 000008 /proc/irq/78/smp_affinity 000010 /proc/irq/79/smp_affinity 000020 /proc/irq/80/smp_affinity 000040 /proc/irq/81/smp_affinity 000080 /sys/class/net/eth0/queues/rx-0/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-1/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-2/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-3/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-4/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-5/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-6/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-7/rps_cpus 0000ffff /sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-4/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-5/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-6/rps_flow_cnt 4096 /sys/class/net/eth0/queues/rx-7/rps_flow_cnt 4096 /proc/sys/net/core/rps_sock_flow_entries 32768测试方法: 每种测试类型执行3次,中间睡眠10秒, 每种测试类型分别执行100、500、1500个实例, 每实例测试时间长度为60秒
TCP_RR 1 byte: 测试TCP 小数据包 request/response的性能
测试结果
TCP_RR 1 byte小包测试TCP_RR 256 byte大包测试
UDP_RR 1 byte小包测试
UDP_RR 256 byte大包测试
CPU核负载的变化
以小数据包1500进程测试的CPU(除了明确指明类型,否则这里的负载都是TCP_RR测试的负载)负载数据为示例不开启IRQ affinity和RPS/RFS: 软中断集中在第一个CPU上,导致了性能瓶颈
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 2.15 0.00 11.35 0.00 0.00 5.66 0.00 0.00 80.84 Average: 0 0.12 0.00 0.65 0.00 0.00 90.86 0.00 0.00 8.38 Average: 1 8.36 0.00 37.46 0.00 0.00 0.00 0.00 0.00 54.19 Average: 2 7.92 0.00 32.94 0.00 0.00 0.00 0.00 0.00 59.13 Average: 3 5.68 0.00 23.96 0.00 0.00 0.00 0.00 0.00 70.36 Average: 4 0.78 0.00 9.77 0.07 0.00 0.00 0.00 0.00 89.39 Average: 5 0.67 0.00 8.87 0.00 0.00 0.00 0.00 0.00 90.47 Average: 6 0.77 0.00 6.91 0.00 0.00 0.00 0.00 0.00 92.32 Average: 7 0.50 0.00 5.55 0.02 0.00 0.00 0.00 0.00 93.93 Average: 8 7.29 0.00 37.16 0.00 0.00 0.00 0.00 0.00 55.55 Average: 9 0.35 0.00 2.28 0.00 0.00 0.00 0.00 0.00 97.37 Average: 10 0.27 0.00 2.01 0.00 0.00 0.00 0.00 0.00 97.72 Average: 11 0.25 0.00 1.87 0.00 0.00 0.00 0.00 0.00 97.88 Average: 12 0.23 0.00 2.78 0.00 0.00 0.00 0.00 0.00 96.99 Average: 13 0.27 0.00 2.70 0.00 0.00 0.00 0.00 0.00 97.04 Average: 14 0.55 0.00 3.03 0.02 0.00 0.00 0.00 0.00 96.40 Average: 15 0.10 0.00 2.16 0.00 0.00 0.00 0.00 0.00 97.74单独开启RPS/RFS: 软中断主要集中在CPU0上,但有少许分布在其他CPU上
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 4.65 0.00 34.71 0.01 0.00 7.37 0.00 0.00 53.26 Average: 0 0.02 0.00 0.37 0.00 0.00 99.40 0.00 0.00 0.22 Average: 1 5.60 0.00 38.33 0.02 0.00 2.02 0.00 0.00 54.04 Average: 2 5.57 0.00 37.33 0.03 0.00 1.01 0.00 0.00 56.05 Average: 3 5.11 0.00 36.28 0.00 0.00 0.73 0.00 0.00 57.88 Average: 4 4.78 0.00 37.16 0.00 0.00 2.05 0.00 0.00 56.01 Average: 5 4.45 0.00 37.46 0.00 0.00 0.97 0.00 0.00 57.12 Average: 6 4.34 0.00 36.25 0.00 0.00 0.97 0.00 0.00 58.45 Average: 7 4.28 0.00 35.87 0.00 0.00 0.97 0.00 0.00 58.88 Average: 8 5.47 0.00 37.11 0.02 0.00 1.27 0.00 0.00 56.13 Average: 9 5.58 0.00 37.59 0.03 0.00 2.13 0.00 0.00 54.66 Average: 10 5.98 0.00 37.04 0.00 0.00 1.22 0.00 0.00 55.76 Average: 11 4.99 0.00 34.58 0.00 0.00 0.99 0.00 0.00 59.44 Average: 12 4.46 0.00 37.47 0.00 0.00 0.99 0.00 0.00 57.09 Average: 13 4.83 0.00 36.97 0.00 0.00 1.37 0.00 0.00 56.83 Average: 14 4.60 0.00 38.06 0.00 0.00 1.53 0.00 0.00 55.81 Average: 15 4.36 0.00 37.26 0.00 0.00 1.45 0.00 0.00 56.92单独开启IRQ affinity, TCP_RR测试: 软中断负载比较均匀的分散到前面8个CPU之上(与bitmask设置一致)
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 6.13 0.00 55.66 0.00 0.00 32.04 0.00 0.00 6.17 Average: 0 6.31 0.00 54.49 0.03 0.00 4.19 0.00 0.00 34.98 Average: 1 2.00 0.00 16.65 0.00 0.00 81.35 0.00 0.00 0.00 Average: 2 3.31 0.00 29.36 0.00 0.00 64.58 0.00 0.00 2.76 Average: 3 2.91 0.00 23.11 0.00 0.00 71.40 0.00 0.00 2.58 Average: 4 2.48 0.00 20.82 0.00 0.00 75.30 0.00 0.00 1.40 Average: 5 2.49 0.00 21.90 0.00 0.00 73.30 0.00 0.00 2.31 Average: 6 3.00 0.00 28.87 0.00 0.00 65.96 0.00 0.00 2.17 Average: 7 2.58 0.00 22.95 0.00 0.00 72.46 0.00 0.00 2.01 Average: 8 6.61 0.00 56.48 0.00 0.00 0.00 0.00 0.00 36.90 Average: 9 9.83 0.00 89.28 0.00 0.00 0.05 0.00 0.00 0.83 Average: 10 9.73 0.00 87.18 0.00 0.00 0.00 0.00 0.00 3.08 Average: 11 9.73 0.00 88.08 0.00 0.00 0.05 0.00 0.00 2.14 Average: 12 9.11 0.00 88.71 0.00 0.00 0.05 0.00 0.00 2.12 Average: 13 9.43 0.00 89.53 0.00 0.00 0.03 0.00 0.00 1.00 Average: 14 9.38 0.00 87.58 0.00 0.00 0.03 0.00 0.00 3.00 Average: 15 9.53 0.00 88.97 0.00 0.00 0.07 0.00 0.00 1.43单独开启IRQ affinity, UDP_RR测试: 软中断负载不能均匀的分散到前面8个CPU之上,主要分布在CPU2上,导致了瓶颈,性能下降(下降原因请见本文测试的局限性部分)
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 1.05 0.00 8.21 0.01 0.00 5.83 0.00 0.00 84.90 Average: 0 3.10 0.00 23.25 0.00 0.00 0.33 0.00 0.00 73.31 Average: 1 2.73 0.00 21.15 0.00 0.00 0.37 0.00 0.00 75.75 Average: 2 0.72 0.00 4.93 0.00 0.00 92.35 0.00 0.00 2.00 Average: 3 1.27 0.00 9.81 0.00 0.00 0.10 0.00 0.00 88.82 Average: 4 0.15 0.00 1.87 0.10 0.00 0.07 0.00 0.00 97.82 Average: 5 0.07 0.00 1.04 0.00 0.00 0.07 0.00 0.00 98.82 Average: 6 0.02 0.00 0.53 0.00 0.00 0.03 0.00 0.00 99.42 Average: 7 0.00 0.00 0.23 0.00 0.00 0.00 0.00 0.00 99.77 Average: 8 0.23 0.00 1.96 0.00 0.00 0.00 0.00 0.00 97.81 Average: 9 0.08 0.00 0.60 0.00 0.00 0.00 0.00 0.00 99.32 Average: 10 8.38 0.00 65.07 0.00 0.00 0.00 0.00 0.00 26.56 Average: 11 0.00 0.00 0.36 0.00 0.00 0.00 0.00 0.00 99.64 Average: 12 0.03 0.00 0.23 0.00 0.00 0.00 0.00 0.00 99.73 Average: 13 0.00 0.00 0.19 0.00 0.00 0.00 0.00 0.00 99.81 Average: 14 0.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00 99.88 Average: 15 0.02 0.00 0.10 0.00 0.00 0.00 0.00 0.00 99.88同时开启IRQ affinity和RPS/RFS: 软中断负载比较均匀的分散到各个CPU之上
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 6.27 0.00 53.65 0.00 0.00 32.33 0.00 0.00 7.74 Average: 0 7.05 0.00 59.70 0.00 0.00 26.18 0.00 0.00 7.07 Average: 1 5.44 0.00 43.33 0.00 0.00 44.54 0.00 0.00 6.69 Average: 2 5.49 0.00 43.06 0.00 0.00 43.38 0.00 0.00 8.07 Average: 3 5.48 0.00 44.90 0.00 0.00 42.94 0.00 0.00 6.67 Average: 4 4.74 0.00 43.27 0.00 0.00 45.14 0.00 0.00 6.85 Average: 5 4.83 0.00 41.90 0.00 0.00 46.74 0.00 0.00 6.53 Average: 6 5.04 0.00 44.73 0.00 0.00 43.68 0.00 0.00 6.56 Average: 7 4.85 0.00 44.68 0.00 0.00 45.22 0.00 0.00 5.25 Average: 8 7.60 0.00 61.50 0.02 0.00 22.79 0.00 0.00 8.08 Average: 9 7.40 0.00 61.31 0.00 0.00 22.92 0.00 0.00 8.37 Average: 10 7.74 0.00 60.62 0.00 0.00 22.64 0.00 0.00 9.00 Average: 11 8.22 0.00 61.02 0.00 0.00 22.13 0.00 0.00 8.63 Average: 12 6.53 0.00 62.42 0.00 0.00 22.09 0.00 0.00 8.97 Average: 13 6.68 0.00 62.75 0.00 0.00 22.13 0.00 0.00 8.43 Average: 14 6.62 0.00 62.41 0.00 0.00 22.69 0.00 0.00 8.28 Average: 15 6.64 0.00 60.66 0.00 0.00 22.38 0.00 0.00 10.32
结果分析
1. TCP_RR TPS小数据包性能
单独开启RPS/RFS分别提升60%,145%,200%(依次对应100进程,500进程,1500进程,下同)单独开启IRQ affinity分别提升135%, 343%, 443%
同时开启RPS/RFS和IRQ affinity分别提升148%, 346%, 372%
2. TCP_RR TPS大数据包性能
单独开启RPS/RFS分别提升76%,77%,89%单独开启IRQ affinity分别提升79%, 77%, 88%
同时开启RPS/RFS和IRQ affinity分别提升79%, 77%, 88%
3. UDP_RR TPS小数据包性能
单独开启RPS/RFS分别提升44%,103%,94%单独开启IRQ affinity性能分别下降11%, 8%, 8% (这是此次测试的局限造成, 详细分析见: 测试的局限性)
同时开启RPS/RFS和IRQ affinity分别提升65%, 130%, 137%
4. UDP_RR TPS小数据包性能
单独开启RPS/RFS分别提升55%,53%,61%单独开启IRQ affinity性能分别下降5%, 4%, 4%
同时开启RPS/RFS和IRQ affinity分别提升55%, 51%, 53%
TCP 小数据包应用上,单独开启IRQ affinity能获得最大的性能提升,随着进程数的增加,IRQ affinity的优势越加明显.
UDP 小数据包方面,由于此次测试的局限,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升;
TCP 大数据包应用上,单独开启IRQ affinity性能提升没有小数据包那么显著,但也有接近80%的提升, 基本与单独开启RPS/RFS的性能持平, 根据实验的数据计算所得,此时网卡流量约为88MB,还没达到千兆网卡的极限。
UDP 大数据包应用上,也是同样受测试局限性的影响,无法真实体现实际应用中的单独开启IRQ affinity而获得的性能提升, 但用RPS/RFS配合IRQ affinity,也能获得大幅度的性能提升
测试的局限性
对于UDP测试在IRQ affinity上性能的下降, 查阅了内核源码(drivers/net/bnx2.c)及资料, bnx2 网卡的RSS hash不支持对UDP的端口进行计算,从而导致单独启用IRQ affinity的时候(这时候由硬件进行hash计算), UDP的数据只被hash了IP地址而导致数据包的转发出现集中在某个CPU的现象. 这是此次测试的局限所在,由于测试只是一台服务器端及一台客户端,所有UDP的IP地址都相同,无法体现UDP性能在单独启用IRQ affinity的性能提升. 但RPS/RFS的hash计算不受硬件影响,故而能体现性能提升. 对于实际应用中,服务器与多台客户端交互的情形,应该不受bnx2的RSS hash影响(以上只是针对bnx2网卡的特定问题)相关对比测试
1. Linux内核 RPS/RFS功能详细测试分析: http://www.igigo.net/archives/204参考资料
IRQ affinityScaling in the Linux Networking Stack
Linux 多核下绑定硬件中断到不同 CPU(IRQ Affinity)
计算 SMP IRQ Affinity
bnx2 RSS hash
Introduction to Receive-Side Scaling
RPS和RFS
RPS 全称是 Receive Packet Steering, 这是Google工程师 Tom Herbert (therbert@google.com )提交的内核补丁, 在2.6.35进入Linux内核. 这个patch采用软件模拟的方式,实现了多队列网卡所提供的功能,分散了在多CPU系统上数据接收时的负载, 把软中断分到各个CPU处理,而不需要硬件支持,大大提高了网络性能。RFS 全称是 Receive Flow Steering, 这也是Tom提交的内核补丁,它是用来配合RPS补丁使用的,是RPS补丁的扩展补丁,它把接收的数据包送达应用所在的CPU上,提高cache的命中率。
这两个补丁往往都是一起设置,来达到最好的优化效果, 主要是针对单队列网卡多CPU环境(多队列多重中断的网卡也可以使用该补丁的功能,但多队列多重中断网卡有更好的选择:SMP IRQ affinity)
原理
RPS: RPS实现了数据流的hash归类,并把软中断的负载均衡分到各个cpu,实现了类似多队列网卡的功能。由于RPS只是单纯的把同一流的数据包分发给同一个CPU核来处理了,但是有可能出现这样的情况,即给该数据流分发的CPU核和执行处理该数据流的应用程序的CPU核不是同一个:数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对于cpu cache的影响会很大。那么RFS补丁就是用来确保应用程序处理的cpu跟软中断处理的cpu是同一个,这样就充分利用cpu的cache。应用RPS之前: 所有数据流被分到某个CPU, 多CPU没有被合理利用, 造成瓶颈
应用RPS之后: 同一流的数据包被分到同个CPU核来处理,但可能出现cpu cache迁跃
应用RPS+RFS之后: 同一流的数据包被分到应用所在的CPU核
解析Linux 2.6.35 新增特性―――什么是RPS和RFS
Linux 2.6.35于2010年8月1号发布,新增特性比较多,而其中最引我注意的为第一点:Transparent spreading of incoming network traffic load across CPUs。关于此点改进的详细介绍可以查看LWN上的两篇文章:"Receive packet steering" and "Receive flow steering"。
下面我就自己的理解来做一下阐述,不当之处,多多包涵。
首先是Receive Packet Steering (RPS)
随着单核CPU速度已经达到极限,CPU向多核方向发展,要持续提高网络处理带宽,传统的提升硬件设备、智能处理(如GSO、TSO、UFO)处理办法已不足够。如何充分利用多核势来进行并行处理提高网络处理速度就是RPS解决的课题。
以一个具有8核CPU和一个NIC的,连接在网络中的主机来说,对于由该主机产生并通过NIC发送到网络中的数据,CPU核的并行性是自热而然的事情:
问题主要在于当该主机通过NIC收到从网络发往本机的数据包时,应该将数据包分发给哪个CPU核来处理(有些具有多条接收队列和多重中断线路的NIC可以帮助数据包并行分发,这里考虑普通的NIC,普通的NIC通过RPS来模拟实现并行分发):
普通的NIC来分发这些接收到的数据包到CPU核处理需要一定的知识智能以帮助提升性能,如果数据包被任意的分配给某个CPU核来处理就可能会导致所谓的“cacheline-pingpong”现象:
比如DATA0数据流的第一个包被分发给CPU0来处理,第二个包分发给CPU1处理,第三个包又分发给CPU0处理;而DATA1数据流恰好相反。这样的交替轮换(8核情况交替得更随意)会导致CPU核的CACHE利用过分抖动。
RPS就是消除这种CPU核随意性分配的智能知识,它通过数据包相关的信息(比如IP地址和端口号)来创建CPU核分配的hash表项,当一个数据包从NIC转到内核网络子系统时就从该hash表内获取其对应分配的CPU核(首次会创建表项)。这样做的目的很明显,它将具有相同相关信息(比如IP地址和端口号)的数据包都被分发给同一个CPU核来处理,避免了CPU的CACHE抖动现象,提高处理性能。
有两点细节:
第一,所有CPU核具有等同的被绑定几率,但管理员可以明确设置CPU核的绑定情况;
第二,hash表项的计算是由NIC进行的,不消耗CPU。
RPS的性能优化结果为大致可提升3倍左右。tg3驱动的NIC性能由90,000提升到285,000,而e1000驱动的NIC性能由90,000提升到292,000,其它驱动NIC也得到类似的测试结果。
接下来是Receive flow steering (RFS)
RFS是在RPS上的改进,从上面的介绍可以看到,通过RPS已经可以把同一流的数据包分发给同一个CPU核来处理了,但是有可能出现这样的情况,即给该数据流分发的CPU核和执行处理该数据流的应用程序的CPU核不是同一个:
不仅要把同一流的数据包分发给同一个CPU核来处理,还要分发给其‘被期望’的CPU核来处理就是RFS需要解决的问题。
RFS会创建两个与数据包相关信息(比如IP地址和端口号)的CPU核映射hash表:
1. 一个用于表示期望处理具有该类相关信息数据包的CPU核映射,通过recvmsg()或sendmsg()等系统调用信息来创建该hash表(称之为期望CPU表)。比如运行于CPU0核上的某应用程序调用了recvmsg()从远程机器host1上获取数据,那么NIC对从host1上发过来的数据包的分发期望CPU核就是CPU0。
2. 一个用于表示最近处理过具有该类相关信息数据包的CPU核映射,称这种表为当前CPU表。该表的存在是因为有多线程的情况,比如运行在两个CPU核上的多线程程序(每个核运行一个线程)交替调用recvmsg()系统函数从同一个socket上获取远程机器host1上的数据会导致期望CPU表频繁更改。如果数据包的分发仅由期望CPU表决定则会导致数据包交替分发到这两个CPU核上,很明显,这不是我们想要的效果。
既然CPU核的分配由两个hash表值决定,那么就可以有一个算法来描述这个决定过程:
1. 如果当前CPU表对应表项未设置或者当前CPU表对应表项映射的CPU核处于离线状态,那么使用期望CPU表对应表项映射的CPU核。
2. 如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核为同一个,那么好办,就使用这一个核。
3. 如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核不为同一个,那么:
a) 如果同一流的前一段数据包未处理完,那么必须使用当前CPU表对应表项映射的CPU核,以避免乱序。
b) 如果同一流的前一段数据包已经处理完,那么则可以使用期望CPU表对应表项映射的CPU核。
算法的前两步比较好理解,而对于第三步可以用下面两个图来帮助理解。应用程序APP0有两个线程THD0和THD1分别运行在CPU0核和CPU1核上,同时CPU1核上还运行有应用程序APP1。首先THD1调用recvmsg()获取远程数据(数据流称之为FLOW0),此时FLOW0的期望CPU核为CPU1,随着数据块FLOW0 : 0的到来并交给CPU1核处理,此时FLOW0的当前CPU核也为CPU1。如果此时THD0也在同一个socket上调用recvmsg()获取远程数据(数据流同样也是FLOW0),那么FLOW0的期望CPU核就改变为CPU0(当前CPU核仍然为CPU1)。与此同时,NIC收到数据块FLOW0 : 1,如何将该数据块分发给CPU核就到了上面算法的第三步。
分情况判断:
1. 如果同一流的前一段数据包FLOW0 : 0未处理完,那么必须使用当前CPU核CPU1来处理新到达的数据块,以避免乱序。如下图所示(FLOW1流是应用程序APP1的):
2. 如果同一流的前一段数据包FLOW0 : 0已经处理完毕,那么可以使用期望CPU核CPU0来处理新到达的数据块。如下图所示(FLOW1流是应用程序APP1的):
RFS适用于面向流的网络协议,它能更好的提升CPU的CACHE效率,不论是内核还是应用程序本身。RFS的性能优化结果在普通环境下为大致可提升3倍左右,而在多线程环境大致可提升2倍。能通过软件的形式提升机器网络带宽性能自然也是再好不过的事情了。
可以参考人人网运维兄弟的文章:
/article/4256365.html
2014-06-18
今天观察了一下web服务器,发现如下问题,当没有绑定软中断的时候,us的cpu都是压在偶数核上面
软中断配置如下:
for i in ` cat /proc/interrupts|grep eth|awk -F":" '{print $1}'`; do cat /proc/irq/$i/smp_affinity; done
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
7fffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff,ffffffff
以下是top看到情况:
Cpu0 : 60.5%us, 6.6%sy, 0.0%ni, 17.6%id, 0.0%wa, 1.0%hi, 14.3%si, 0.0%st
Cpu1 : 2.0%us, 1.0%sy, 0.0%ni, 97.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 22.9%us, 4.3%sy, 0.0%ni, 72.4%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu3 : 4.0%us, 1.0%sy, 0.0%ni, 95.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu4 : 26.9%us, 4.3%sy, 0.0%ni, 68.1%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu5 : 1.0%us, 0.7%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu6 : 26.2%us, 4.0%sy, 0.0%ni, 69.4%id, 0.0%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu7 : 2.0%us, 0.7%sy, 0.0%ni, 96.3%id, 0.7%wa, 0.0%hi, 0.3%si, 0.0%st
Cpu8 : 39.2%us, 5.3%sy, 0.0%ni, 54.5%id, 0.0%wa, 0.0%hi, 1.0%si, 0.0%st
Cpu9 : 2.7%us, 2.0%sy, 0.0%ni, 95.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu10 : 29.9%us, 6.0%sy, 0.0%ni, 63.5%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu11 : 1.3%us, 2.0%sy, 0.0%ni, 96.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu12 : 26.0%us, 5.0%sy, 0.0%ni, 68.3%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu13 : 2.0%us, 1.7%sy, 0.0%ni, 96.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu14 : 27.9%us, 4.0%sy, 0.0%ni, 67.4%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st
Cpu15 : 2.7%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 97.3%si, 0.0%st
当绑定软中断之后,都是压在固定的几个cpu核上,奇怪了。

相关文章推荐
- 关于北京地铁通车计划
- 北京副市长要求地铁车厢不得超载
- 听见丨北京地铁全路网今起可手机购票 俄男子玩VR时摔倒划伤致死
- 听见丨北京首条无人驾驶地铁年底开通 单程25分钟 2017年全球最富有的人财富又增加了1万亿美元
- 【地铁】北京地铁退卡点
- 北京地铁站点
- 北京地铁线路规划程序
- Windows phone 北京地铁软件实现
- [北京交通]今天早上骑自行车上班,比坐地铁晚了5分钟
- 北京地铁之五道口
- 生活就像北京的地铁1
- 涨姿势!北京地铁原来是16条旅游专线
- 转载一篇文章 写的很好 关于北京地铁涨价的
- 北京:地铁春运16日开始 客流将同比增长一成
- 北京4条在建地铁将提前开通 10号线二期明年通
- 2012返回北京在地铁上的心情
- 北京地铁规划(1到13号线全有)
- 北京地铁规划大全(图),买房子可以参考一下
- 北京2008年地铁规划收集
- 喜大普奔!北京地铁正式支持刷手机:苹果安卓全线兼容