网络蜘蛛程序开发
2006-03-26 06:18
295 查看
什么是网络蜘蛛
网络蜘蛛是一种能自动到网上查找信息的一种程序,该程序具有高度的自动性,只要告诉他一个网站,他就可以从这个网站开始依次通过该网站的链接自动抓取链接内容以及网址,然后就顺着这些链接一直抓下去。网络蜘蛛可以方便的实现从网络中抓取信息并且保存到当地数据库。
智能型的网络蜘蛛甚至可以抓取您指定的信息并自动过滤掉不相关的信息,替代重复的人工操作。
网络蜘蛛运行时必须设置种子网站,设置的种子网站必须可以链接下去,否则可能会造成蜘蛛停止工作。因此我们在设置种子网站时可以设置比较大型的、链接比较多的网站,当然您也可以设置多个种子网站以确保网络蜘蛛能运行足够长的时间。
蜘蛛程序网站层次及其工作原理描述
| 序号 | 网站 | 层次 | 父序号 |
| 1 | http://www.netfox.cn/ | 1 | 0 |
| 2 | http://www.sina.com.cn/ | 2 | 1 |
| 3 | http://www.cnnic.cn/ | 2 | 1 |
| 4 | http://www.baidu.cn/ | 3 | 2 |
| 5 | http://www.yahoo.cn/ | 3 | 2 |
蜘蛛程序首先从层次1(http://www.netfox.cn/)开始提取所有的网站链接,把所有网站链接记录到数据库(或者大数组等),并把这些网站链接标识为层次2;
当把层次2全部记录到数据库后,开始从层次2中顺序为第一的(这里指序号为2的网站)网站链接开始提取其下面的的所有链接记录到数据库,并把这些网站链接标识为层次3;然后依次把层次为2的网站的所有链接记录到数据库,同时把他们的层次标识为层次3;
当层次3全部记录数据库后,开始从层次3中顺序为第一的网站链接开始提取,依次类推即可!
注意:程序要保留一个指针记录当前正在操作的序号!另外您也可以增加一个父序号字段来记录他们之间的继承关系!
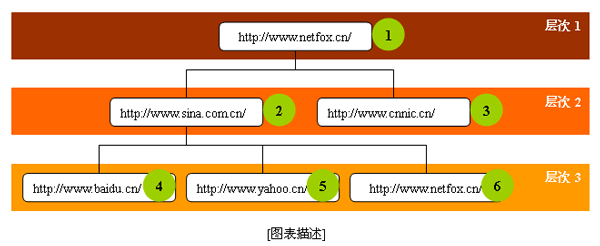
层次1表示为网络种子;我们这里把网络种子放在第一层,根据需要您可以设置一个或者多个网络种子,实际上我们通过这个层次图可以很显然地看出来,低层次的网址就是高层次的网络种子。也就是说只要有一个或者几个网络种子,我们就可以通过他们的链接找到更多的网络种子。只要这样我们的蜘蛛才能永远地运行下去!
层次2是通过层次1(即网络种子)抓取到的链接;
层次3是通过层次2抓取到的链接;
依次类推,构成一棵大树!
蜘蛛程序关键代码
由于我对VB比较熟悉,所以在此我用VB实现核心部分的代码,当然您也可以很简单地转换成其他语言代码。在这里了为了简单起见,我们这里不对数据库操作,我们建立一个二维数组存放我们的网址!!Dim Web(4,10000) ‘//建立数组
Dim Pointer ‘//建立指针,记录当前种子
Dim Id ‘//建立序号,记录当前抓区网站的序号
Dim Layer ‘//建立层次,记录当前正在运行种子的层次
Dim Running ‘//建立是否运行的标志,
Private Function NewworkSeed_Set() As Boolean ‘//用来设置网络种子,为演示方便我们把种子放在数组,
'//当然您也可以根据需要把他们直接放到数据库中
Web(0,0) = 1 ‘//序号
Web(1,0) = “http://www.netfox.cn/” ‘//网站
Web(2,0) = 1 ‘//层次
Web(3,0) = 0 ‘//父序号,0表示为网络原始种子
Web(4,0) = “奈福网络”
‘//当然这里可以设置多个网络原始种子
Web(0,1) = 1
Web(1,1) = “http://www.aspfaq.cn/”
Web(2,1) = 1
Web(3,1) = 0
Web(4,1) = “asp技术站”
‘//设置网络种子后,记录种子序号开始后的序号,这里设置了2个种子,所以Id=2开始
Id = 2
End Function
Private Sub Spider_Work() ‘//蜘蛛工作程序,抓取网站并记录到数组
‘//根据需要可以把他们放到数据库中
Dim A
For Each A In WebBrowser.Document.All
If UCase(A.tagName) = "A" Then
If IsValidWeb(A.href) Then
Id = Id + 1
Web(0, Id) = Id ‘//记录当前网站的序号
Web(1, Id) = A.href ‘//记录当前网站
Web(2, Id) = Layer ‘//记录当前网站的层次
If Web(2,Pointer)<> Layer Then Layer = Layer + 1 ‘//当指针层次与当前层次不同的话
‘//则说明层次已经发生了增加
Web(3, Id) = Pointer ‘//记录当前网站的父序号
Web(4,Id) = A.innerText ‘//记录当前网站的名称
End If
End If
Next
Pointer = Pointer + 1
WebBrowser.Navigate Web(1, Pointer-1) ‘//抓取当前种子完毕后,自动跳转到下一个种子
If Running = False Then ‘//运行为否,退出运行
Exit Sub
End If
End Sub
Private Function Spider_Init() As Boolean ‘//蜘蛛程序初始化函数
Pointer = 1 ‘//指针设置为1,表示从第一个序号开始运行
Id = 2 ‘//序号设置为2,以后可以读取记录
Layer = 0 ‘//层次设置为0,表示蜘蛛第一次运行
‘//以上指针,序号,层次都可以记录并且方便以后读取
If IsValidWeb(Web(1, Pointer-1)) Then ‘//判断种子是否正确,如果正确初始化成功,否则失败
Running = True
Spider_Init = True
WebBrowser.Navigate Web(1, Pointer-1)
Else
Running = False
Spider_Init = False
Exit Function
End If
End Function
Private Sub WebBrowser_DocumentComplete(ByVal pDisp As Object, URL As Variant) ‘//WebBrowser控件
Call Spider_Work()
End Sub
Private Function IsValidWeb(_href) As Boolean ‘//判断是否是cn域名函数
‘//通过该函数可以实现抓取指定网站或数据
If InStr(_href, "http://www.") > 0 And InStr(_href, ".cn/") > 0 And Len(_href) < 60 Then
IsValidWeb = True
Else
IsValidWeb = False
End If
End Function
Private Sub InitCommand_Click() ‘//Init初始化 命令控件
If Spider_Init() Then
Msgbox “蜘蛛初始化成功并开始运行了”
Else
Msgbox “蜘蛛初始化失败”
End If
End Private
Private Sub StopCommand_Click() ‘//Stop停止 命令控件
Running = False ‘//停止运行
End Private
Private Sub RunCommand_Click() ‘//Run运行 命令控件
Running = True ‘//继续运行
Call Spider_Work() ‘//蜘蛛运行主程序
End Private

相关文章推荐
- 网络蜘蛛程序开发
- 网络蜘蛛程序开发
- 用C#开发蜘蛛网络爬虫采集程序(附源码)(二)
- 用C#开发蜘蛛网络爬虫采集程序(附源码)(一)
- WINSOCK开发网络通信程序的经典入门——解释异步等概念
- 开发适应中国网络的J2ME连网程序(转)
- 使用网络提供的web服务开发航班查询程序
- C#.Net网络程序开发-Socket篇
- Visual C#.Net网络程序开发之TCP/IP
- 异步非阻塞套接字Winsock开发网络通信程序的经典入门
- C#.Net网络程序开发-Socket篇(转)
- Visual C#.Net 网络程序开发-Socket篇
- Visual C#.Net网络程序开发-Tcp篇(3)
- Visual C#.Net网络程序开发-Tcp篇(1)
- 网络游戏服务器开发::学习了两天python写了一个linux下自动安装程序的脚本
- Visual C#.Net 网络程序开发(转载)
- C#.Net网络程序开发-Socket篇
- Visual C#.Net 网络程序开发-Socket篇
- 网络蜘蛛程序的设计与实现(三)网页分析算法
- 异步非阻塞套接字Winsock开发网络通信程序的经典入门